There have been various posts to reddit, and various discussions in the last few days of slides from talks I've given on Supero. It's nice to see that people are interested, but some people have got slightly wrong impressions based on either the fact that talks don't include the bit I say, or that the material has moved on since the talk was written. I wasn't going to post my revised paper (currently undergoing refereeing) - but since it addresses both those issues perfectly, I decided to put in on the project web page:
http://www-users.cs.york.ac.uk/~ndm/downloads/draft-supero-10_dec_2007.pdf
I'm also going to address some of the questions people might ask:
It is possible to write charcount 8 times faster with mmap
Yes. You are correct. It may even be quite a bit more than 8 times. However, the benchmark controls for this - all programs only use getchar. The idea is not to write the worlds fastest letter counting program, either use hFileSize or Data.ByteString for that. The idea is to have a benchmark with computation which has abstracted away the non-computation bit until C and Haskell can be compared as directly as possible.
It's also a useful micro-benchmark. It's not too long and complex. It's a real task that people can wrap their heads around. There is a nice gentle progression between char/line/word counting. There are lots of good reasons for picking these benchmarks, but don't think of them as being too important - think of them as "ah, that's cute".
What's new with this paper?
If you've read the last paper, or seen a talk I've given, there are major differences in this paper. The largest change is that instead of waving my hands and trying to distract people with shiny things when the topic of non-termination comes up, I now have a good answer. The answer is homeomorphic embedding. I got this technique from Peter Jonsson, who in turn got it off Morten Sørensen and Robert Glück. It turns out my supervisor also used it in his thesis!
There are other differences all over the place. I've managed to get results for most of the imaginary section of the nofib suite (12 benchmarks). I've also come up with a new generalisation strategy, have a better story of what to do with let's, and have tried to make my optimisation better defined.
What now?
I want the the compilation times to be faster, the results to be better and more results on more benchmarks. Compilation times are between 10 seconds and 5 minutes, on a normal computer. Unfortunately my home machine isn't normal, it's 8 years old. I am hoping to improve the compilation speed to about the 2 second level, then I am going to do lots more benchmarks and investigate those where the optimisation doesn't do as well as I was hoping.
Tuesday, December 11, 2007
Friday, November 30, 2007
Nofib benchmarks
I've been working right through the night for the IFL post-publication deadline, trying to get benchmarks for most of the imaginary nofib suite using Supero. It's now almost 9am, and I'm off to work once more, so here are the final raw results I'm going to be using in the IFL paper.
For these numbers, lower is better. The fastest optimiser gets a 1.00, all the others are scaled relative to it. The most red value is the slowest. ghc2 is GHC 6.8.1 with -O2. supero-* is running through the Yhc front end, then through Supero, then through GHC 6.8.1 -O2. none corresponds to the supero optimiser doing no inlining or optimisation, essentially giving GHC the whole program in one go. The other supero-* results are all based on Positive Supercompilation with homeomorphic embedding as the termination criteria and a given generalisation function. whistle is no generalisation criteria, msg is the most specific generalisation, and general is my newly created generalisation function. All the details will be in the paper I'm submitting later today.
I know some places where these results have fallen a bit flat of what they should, but even so, I'm very happy with this!
For these numbers, lower is better. The fastest optimiser gets a 1.00, all the others are scaled relative to it. The most red value is the slowest. ghc2 is GHC 6.8.1 with -O2. supero-* is running through the Yhc front end, then through Supero, then through GHC 6.8.1 -O2. none corresponds to the supero optimiser doing no inlining or optimisation, essentially giving GHC the whole program in one go. The other supero-* results are all based on Positive Supercompilation with homeomorphic embedding as the termination criteria and a given generalisation function. whistle is no generalisation criteria, msg is the most specific generalisation, and general is my newly created generalisation function. All the details will be in the paper I'm submitting later today.
I know some places where these results have fallen a bit flat of what they should, but even so, I'm very happy with this!
| ghc2 | supero-general | supero-msg | supero-none | supero-whistle | |
| bernouilli | 1.00 | 1.41 | 1.53 | 1.18 | 1.58 |
| digits-of-e1 | 1.00 | 1.03 | 1.16 | 1.06 | 1.03 |
| digits-of-e2 | 1.39 | 1.00 | 1.00 | 2.58 | 1.00 |
| exp3_8 | 1.00 | 1.00 | 1.00 | 1.01 | 1.00 |
| integrate | 2.19 | 1.00 | 1.03 | 8.79 | 1.00 |
| primes | 1.76 | 1.00 | 1.00 | 1.69 | 1.54 |
| queens | 1.26 | 1.00 | 1.21 | 1.52 | 1.05 |
| rfib | 1.03 | 1.00 | 1.00 | 1.03 | 1.00 |
| tak | 1.38 | 1.00 | 1.92 | 1.92 | 1.92 |
| wheel-sieve1 | 1.02 | 1.00 | 1.13 | 5.33 | |
| wheel-sieve2 | 1.58 | 1.37 | 1.00 | 1.00 | 1.40 |
| x2n1 | 1.71 | 1.00 | 1.09 | 5.19 | 2.76 |
Sunday, November 25, 2007
PowerPoint -> PDF (Part 2)
After writing a VBA Macro to convert a PowerPoint with animation into a flat PowerPoint without animation (suitable for conversion to PDF), I wrote my talk. After writing my talk I realised I not only needed elements to appear on a click, but also disappear and reappear. Unfortunately my original macro script did not do that, so I've updated it with two new features:
Safer
The original code removed all slides which were not hidden to return to the previous state. Unfortunately, if you haven't yet run the AddElements script, that results in it deleting all your slides! Undo saves the day, but it would be nicer for RemElements to be a bit more considerate. This version tags all the slides it creates, then RemElements simply removes those with the appropriate tag - hopefully this removes the obvious "Doh!" moment from this tool.
Works with show/hide/reshow
The original code used the Shape.AnimationSettings properties to detect what happened to objects. Unfortunately, this property only records the first action associated with an object - I suspect in the past PowerPoint only allowed one action and this is merely here for compatibility. To get the full range of events you need to use the Slide.TimeLine property. Writing the code I ran into two issues: (1) objects with silly names; (2) mutability.
Objects With Silly Names
Some objects have properties which don't do what you might think! Effect.EffectType = msoAnimEffectAppear implies that the animation is to appear, but if Effect.Exit = msoTrue then this is the disappear effect! I was confused by this one for quite a while.
In order to solve all the naming problems, I made extensive use of the Visual Basic debugger included with Office, which puts many other debuggers to shame. It is at least 1000x better than any Haskell debugger I've ever seen, and equally far ahead of things like GDB. Microsoft's software may be maligned, but their debuggers are truly fantastic! It really does allow an entirely new style of development, and is particularly suited to dipping into a new API without having a large learning curve.
Mutability
Mutability is a bad idea. If you delete a shape, while you are iterating over a collection of shapes, you silently skip the element that comes after the deleted shape! If you delete a shape, and that shape is the subject of a transition, then that corresponding transition is deleted. If you change the Shape.AnimationSettings.Animate to msoFalse, this removes any associated transitions. All this means that to try and iterate over something starts to become a challenge!
The problem with mutability in this particular task is that it is unclear what is changing and when, leading to subtle bugs and lots of debugging. Again, the debugger helped, but not as much as before - having to single-step through quite deep properties is not a particularly fun task.
The Code
And here is the code, to be use as in the same way to the previous post.
As before, no warranty, and please do backup first!
Safer
The original code removed all slides which were not hidden to return to the previous state. Unfortunately, if you haven't yet run the AddElements script, that results in it deleting all your slides! Undo saves the day, but it would be nicer for RemElements to be a bit more considerate. This version tags all the slides it creates, then RemElements simply removes those with the appropriate tag - hopefully this removes the obvious "Doh!" moment from this tool.
Works with show/hide/reshow
The original code used the Shape.AnimationSettings properties to detect what happened to objects. Unfortunately, this property only records the first action associated with an object - I suspect in the past PowerPoint only allowed one action and this is merely here for compatibility. To get the full range of events you need to use the Slide.TimeLine property. Writing the code I ran into two issues: (1) objects with silly names; (2) mutability.
Objects With Silly Names
Some objects have properties which don't do what you might think! Effect.EffectType = msoAnimEffectAppear implies that the animation is to appear, but if Effect.Exit = msoTrue then this is the disappear effect! I was confused by this one for quite a while.
In order to solve all the naming problems, I made extensive use of the Visual Basic debugger included with Office, which puts many other debuggers to shame. It is at least 1000x better than any Haskell debugger I've ever seen, and equally far ahead of things like GDB. Microsoft's software may be maligned, but their debuggers are truly fantastic! It really does allow an entirely new style of development, and is particularly suited to dipping into a new API without having a large learning curve.
Mutability
Mutability is a bad idea. If you delete a shape, while you are iterating over a collection of shapes, you silently skip the element that comes after the deleted shape! If you delete a shape, and that shape is the subject of a transition, then that corresponding transition is deleted. If you change the Shape.AnimationSettings.Animate to msoFalse, this removes any associated transitions. All this means that to try and iterate over something starts to become a challenge!
The problem with mutability in this particular task is that it is unclear what is changing and when, leading to subtle bugs and lots of debugging. Again, the debugger helped, but not as much as before - having to single-step through quite deep properties is not a particularly fun task.
The Code
And here is the code, to be use as in the same way to the previous post.
Option Explicit
Sub AddElements()
Dim shp As Shape
Dim i As Integer, n As Integer
n = ActivePresentation.Slides.Count
For i = 1 To n
Dim s As Slide
Set s = ActivePresentation.Slides(i)
s.SlideShowTransition.Hidden = msoTrue
Dim max As Integer: max = AnimationElements(s)
Dim k As Integer, s2 As Slide
For k = 1 To max
Set s2 = s.Duplicate(1)
s2.Name = "AutoGenerated: " & s2.SlideID
s2.SlideShowTransition.Hidden = msoFalse
s2.MoveTo ActivePresentation.Slides.Count
Dim i2 As Integer, h As Shape
Dim Del As New Collection
For i2 = s2.Shapes.Count To 1 Step -1
Set h = s2.Shapes(i2)
If Not IsVisible(s2, h, k) Then Del.Add h
Next
Dim j As Integer
For j = s.TimeLine.MainSequence.Count To 1 Step -1
s2.TimeLine.MainSequence.Item(1).Delete
Next
For j = Del.Count To 1 Step -1
Del(j).Delete
Del.Remove j
Next
Next
Next
End Sub
'is the shape on this slide visible at point this time step (1..n)
Function IsVisible(s As Slide, h As Shape, i As Integer) As Boolean
'first search for a start state
Dim e As Effect
IsVisible = True
For Each e In s.TimeLine.MainSequence
If e.Shape Is h Then
IsVisible = Not (e.Exit = msoFalse)
Exit For
End If
Next
'now run forward animating it
Dim n As Integer: n = 1
For Each e In s.TimeLine.MainSequence
If e.Timing.TriggerType = msoAnimTriggerOnPageClick Then n = n + 1
If n > i Then Exit For
If e.Shape Is h Then IsVisible = (e.Exit = msoFalse)
Next
End Function
'How many animation steps are there
'1 for a slide with no additional elements
Function AnimationElements(s As Slide) As Integer
AnimationElements = 1
Dim e As Effect
For Each e In s.TimeLine.MainSequence
If e.Timing.TriggerType = msoAnimTriggerOnPageClick Then
AnimationElements = AnimationElements + 1
End If
Next
End Function
Sub RemElements()
Dim i As Integer, n As Integer
Dim s As Slide
n = ActivePresentation.Slides.Count
For i = n To 1 Step -1
Set s = ActivePresentation.Slides(i)
If s.SlideShowTransition.Hidden = msoTrue Then
s.SlideShowTransition.Hidden = msoFalse
ElseIf Left$(s.Name, 13) = "AutoGenerated" Then
s.Delete
End If
Next
End Sub
As before, no warranty, and please do backup first!
Saturday, November 24, 2007
Creating a PDF from Powerpoint WITH Custom Animations
Updated: New and improved code can be found at PowerPoint -> PDF (Part 2).
I like to write talks in PowerPoint, because it has a nice interface and is a lot faster to work with for diagrams than Latex. I hope one day to move to using Google's online presentation creation tool, but there is one crucial feature missing that stops me - creating PDF's. If I am going to a place away from York, to present on another persons machine, the format I can guarantee that will display correctly is PDF.
Until now I've never written PowerPoint slides with "custom animations". A custom animation is something as simple as a slide where additional elements become visible with each click, like a pop-out box appearing or a circle around some relevant part of the slide. While its usually sufficient to get away without this feature, it is sometimes very handy. The reason I've stayed away is because of the conversion to PDF.
When Latex creates a slide with many sub-elements which appear at different stages, it creates multiple pages in the PDF. However, when using either OpenOffice's PDF converter or the Acrobat converter all the sub-elements are placed on one slide and are visible at all times - loosing the entire point of hiding elements!
I looked around the web for a tool to solve this problem, without success. I found one tool that seemed like it might help, but appeared to rely on having Acrobat Creator installed locally. I write my presentations on my machine, then remote desktop to the University machines to do the PDF conversion, and on those machines I don't have admin access. In addition, this tool required money to use, and may still not have worked.
Instead I wrote some VBA code, which deconstructs the slides with animations into multiple slides, then puts them back together after. The two macro's are called AddElements and RemElements. The code to AddElements cycles through each slide, duplicating it once for each level of clicky-ness in the animation, deleting the elements that shouldn't be visible yet, and hiding the original.
To run the code go to Tools/Macro/Visual Basic Editor, copy and paste the code into a project, then go to Tools/Macro/Run Macro and run AddElements. You can then use Acrobat to create a standard PDF, and after you are finished, run RemElements to put the project back to the way it was. Like all code you find on the net, please backup your presentation before you start - no warranties are offered or implied!
The code is:
Enjoy!
I like to write talks in PowerPoint, because it has a nice interface and is a lot faster to work with for diagrams than Latex. I hope one day to move to using Google's online presentation creation tool, but there is one crucial feature missing that stops me - creating PDF's. If I am going to a place away from York, to present on another persons machine, the format I can guarantee that will display correctly is PDF.
Until now I've never written PowerPoint slides with "custom animations". A custom animation is something as simple as a slide where additional elements become visible with each click, like a pop-out box appearing or a circle around some relevant part of the slide. While its usually sufficient to get away without this feature, it is sometimes very handy. The reason I've stayed away is because of the conversion to PDF.
When Latex creates a slide with many sub-elements which appear at different stages, it creates multiple pages in the PDF. However, when using either OpenOffice's PDF converter or the Acrobat converter all the sub-elements are placed on one slide and are visible at all times - loosing the entire point of hiding elements!
I looked around the web for a tool to solve this problem, without success. I found one tool that seemed like it might help, but appeared to rely on having Acrobat Creator installed locally. I write my presentations on my machine, then remote desktop to the University machines to do the PDF conversion, and on those machines I don't have admin access. In addition, this tool required money to use, and may still not have worked.
Instead I wrote some VBA code, which deconstructs the slides with animations into multiple slides, then puts them back together after. The two macro's are called AddElements and RemElements. The code to AddElements cycles through each slide, duplicating it once for each level of clicky-ness in the animation, deleting the elements that shouldn't be visible yet, and hiding the original.
To run the code go to Tools/Macro/Visual Basic Editor, copy and paste the code into a project, then go to Tools/Macro/Run Macro and run AddElements. You can then use Acrobat to create a standard PDF, and after you are finished, run RemElements to put the project back to the way it was. Like all code you find on the net, please backup your presentation before you start - no warranties are offered or implied!
The code is:
Sub AddElements()
Dim shp As Shape
Dim i As Integer, n As Integer
n = ActivePresentation.Slides.Count
For i = 1 To n
Dim s As Slide
Set s = ActivePresentation.Slides(i)
s.SlideShowTransition.Hidden = msoTrue
Dim max As Integer: max = 0
For Each shp In s.Shapes
If shp.AnimationSettings.Animate = msoTrue Then
If shp.AnimationSettings.AnimationOrder > max Then
max = shp.AnimationSettings.AnimationOrder
End If
End If
Next
Dim k As Integer, s2 As Slide
For k = 0 To max
Set s2 = s.Duplicate(1)
s2.SlideShowTransition.Hidden = msoFalse
s2.MoveTo ActivePresentation.Slides.Count
Dim i2 As Integer
For i2 = s2.Shapes.Count To 1 Step -1
With s2.Shapes(i2)
If .AnimationSettings.Animate = msoTrue Then
If .AnimationSettings.AnimationOrder > k Then
.Delete
Else
.AnimationSettings.Animate = msoFalse
End If
End If
End With
Next
Next
Next
End Sub
Sub RemElements()
Dim i As Integer, n As Integer
Dim s As Slide
n = ActivePresentation.Slides.Count
For i = n To 1 Step -1
Set s = ActivePresentation.Slides(i)
If s.SlideShowTransition.Hidden = msoTrue Then
s.SlideShowTransition.Hidden = msoFalse
Else
s.Delete
End If
Next
End Sub
Enjoy!
Monday, September 17, 2007
Generics and Germany
The recent Hal2 meeting in Germany has now had some talks posted online. Only one is in English, but it's a nice talk on generic programming. It even mentions my Uniplate library, which was nice to see. There were two points made that I completely agree with:
My interest in generic programming stems from writing programs that manipulate the abstract syntax of a core Haskell-like language. I was completely unaware of all the generics work, and so started to experiment and invent my own library. Almost three years later, after gaining lots of experience about what I did wrong, I had refined Uniplate to the point where I could not imagine programming without it. Had I discovered Scrap Your Boilerplate originally, I probably would not have continued to develop my ideas.
Given the steep learning curve of generic programming, I have deliberately tried to keep Uniplate as simple as possible. I have also tried to write the first two sections of my Uniplate paper from the view of a user, in a slightly tutorial style. If you have a data type with three or more constructors, and perform operations which involve "walking over" values in some way, Uniplate can probably help.
I will be presenting Uniplate at the Haskell Workshop on the 30th of September 2007, and will put the slides up after I return. I will also be presenting Supero (my optimiser) at the IFL conference beforehand, on the 27th. If you are in Germany for IFL/HW/ICFP do come and say hello - my photo is on my website.
- There are lots of generics libraries for Haskell, and even an expert in the field has no hope of understanding all the different design decisions in all the libraries. When writing the related work section for Uniplate it quickly became apparent that to just read all the papers that were related would take forever. Libraries like Control.Applicative can be used for generic programming, but even the authors have "barely begun to explore" its potential. There are lots of libraries, and new ones are still being written. An explosion of ideas is not a bad thing, but at some point some focus will be required.
- The second point is that very few people use generic programming. Generic programming has the potential to massively reduce the volume of code - some real programs that use Uniplate had some complicated functions shrink by five times. Sadly, lots of the generic programming libraries have a rather steep learning curve, and use concepts uncommon in standard Haskell programs. Even given the difficulty at the start, generic programming is certainly worth it in the end, but very few people take the time to learn it. Perhaps once there are a few more users we will get things like a "Generic Programming and Nuclear Waste Tutorial", and the usage will snowball from there.
My interest in generic programming stems from writing programs that manipulate the abstract syntax of a core Haskell-like language. I was completely unaware of all the generics work, and so started to experiment and invent my own library. Almost three years later, after gaining lots of experience about what I did wrong, I had refined Uniplate to the point where I could not imagine programming without it. Had I discovered Scrap Your Boilerplate originally, I probably would not have continued to develop my ideas.
Given the steep learning curve of generic programming, I have deliberately tried to keep Uniplate as simple as possible. I have also tried to write the first two sections of my Uniplate paper from the view of a user, in a slightly tutorial style. If you have a data type with three or more constructors, and perform operations which involve "walking over" values in some way, Uniplate can probably help.
I will be presenting Uniplate at the Haskell Workshop on the 30th of September 2007, and will put the slides up after I return. I will also be presenting Supero (my optimiser) at the IFL conference beforehand, on the 27th. If you are in Germany for IFL/HW/ICFP do come and say hello - my photo is on my website.
Friday, August 24, 2007
Supero: Faster than GHC*
* Warning: Benchmarks are hazardous to your health, always misleading and usually wrong.
I've been working on optimising Haskell with the Supero project for a few months now. I've had some good success with small benchmarks, but scaling up to larger examples is always a challenge. Even a small benchmark, such as those from the imaginary section of nobench, can pull in nearly 1Mb of code from libraries. Debugging through 100,000 lines of low-level transformed Haskell is not pleasant!
Anyway, I now have some results on some of the nobench programs, so I thought I'd share them. As with all benchmarks, there are a whole pile of disclaimers:
With those disclaimers out of the way, on to the graph:
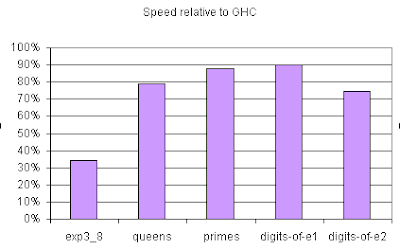
All numbers are given relative to GHC taking 100%, i.e. all the benchmarks are at least 10% faster - and one is nearly three times faster.
It is actually quite an achievement to draw with GHC in these benchmarks. GHC treats class dictionaries in a special manner (I think), and optimises them out specially. GHC also performs a reasonable amount of foldr/build fusion in several of the tests. Since these transformations rely on names and special knowledge, when compiling Yhc generated Haskell they can no longer be applied - so Supero must perform all these tricks to draw with GHC.
I am sure there is further scope for improvement. Supero is a moving target - yesterday the primes benchmark went 50% faster, but now it is only 12% faster. Three days ago I rewrote the whole optimiser. It will be a while before large scale Haskell programs can be optimised, but it is certainly the final goal.
I've been working on optimising Haskell with the Supero project for a few months now. I've had some good success with small benchmarks, but scaling up to larger examples is always a challenge. Even a small benchmark, such as those from the imaginary section of nobench, can pull in nearly 1Mb of code from libraries. Debugging through 100,000 lines of low-level transformed Haskell is not pleasant!
Anyway, I now have some results on some of the nobench programs, so I thought I'd share them. As with all benchmarks, there are a whole pile of disclaimers:
- The benchmarks are unmodified from nobench, unlike last time I have not replaced key functions (i.e. getContents) with alternative versions.
- The Supero programs are optimised by Supero, then fed back into GHC - GHC's excellent native code generation is benefiting both programs.
- All the results are compared to GHC 6.6.1 -O2, which lacks SpecConstr, and is likely to give a benefit to the GHC benchmark.
- The benchmarks were generally chosen because they did not read an input file, and didn't output too much - I wanted this to be a test of computation, not IO. The benchmarks are just the ones I have tackled so far.
- The results are not stable. Yesterday two of the benchmarks showed substantially better results for Supero, and three didn't go through at all. Things are changing fast - there is no guarantee that any final release of Supero will match these numbers.
With those disclaimers out of the way, on to the graph:

All numbers are given relative to GHC taking 100%, i.e. all the benchmarks are at least 10% faster - and one is nearly three times faster.
It is actually quite an achievement to draw with GHC in these benchmarks. GHC treats class dictionaries in a special manner (I think), and optimises them out specially. GHC also performs a reasonable amount of foldr/build fusion in several of the tests. Since these transformations rely on names and special knowledge, when compiling Yhc generated Haskell they can no longer be applied - so Supero must perform all these tricks to draw with GHC.
I am sure there is further scope for improvement. Supero is a moving target - yesterday the primes benchmark went 50% faster, but now it is only 12% faster. Three days ago I rewrote the whole optimiser. It will be a while before large scale Haskell programs can be optimised, but it is certainly the final goal.
Tuesday, August 21, 2007
AnlgoHaskell: The Aftermath
About ten days ago, AngloHaskell 2007 took place. AngloHaskell was a unique meeting, in many respects. I thought it might be appropriate to share my thoughts on the event. With any luck, AngloHaskell will become an annual event.
The first thing that surprised me about AngloHaskell 2007 was the attendance. There are several established academic events in the functional programming community, such as Fun In The Afternoon, ICFP and Haskell Workshop. Of these, only Haskell Workshop has an exclusively Haskell direction, and all are primarily a meeting for academics. On the other side of the coin, there are new Haskell user groups springing up around the world - London, San Francisco, and others - mostly based around a small geographical area. AngloHaskell managed to draw people from as far away as America and Italy, and certainly from far and wide over the UK, both academics, practitioners and those for whom Haskell is a hobby. I was pleasantly surprised by the number of people who don't have any work related to Haskell, but are simply interested.
The first day comprised of talks, which I'll attempt to summarise briefly, with my thoughts:
My slides are online here , and we are collecting the other slides over time.
On the second day we met up, had breakfast, went rowing, then went to the pub. It was not a formal day of talks, but everyone got a chance to chat, discuss some projects and generally get to know each other.
This year Philippa was in charge, with me providing some assistance. Hopefully next year someone else would like to try and organise the event. The helpfulness of the Haskell community makes it a joy - without such a strong community an event like this would never take place.
Finally, I'd like to say thanks again to the speakers, and the people who attended. Also special thanks need to be given to Microsoft Research Cambridge, and in particular Sarah Cater, who provided a venue with catering, and could not have been more helpful!
The first thing that surprised me about AngloHaskell 2007 was the attendance. There are several established academic events in the functional programming community, such as Fun In The Afternoon, ICFP and Haskell Workshop. Of these, only Haskell Workshop has an exclusively Haskell direction, and all are primarily a meeting for academics. On the other side of the coin, there are new Haskell user groups springing up around the world - London, San Francisco, and others - mostly based around a small geographical area. AngloHaskell managed to draw people from as far away as America and Italy, and certainly from far and wide over the UK, both academics, practitioners and those for whom Haskell is a hobby. I was pleasantly surprised by the number of people who don't have any work related to Haskell, but are simply interested.
The first day comprised of talks, which I'll attempt to summarise briefly, with my thoughts:
- Simon Peyton Jones - Indexed type families in Haskell, and death to functional dependencies A really nice summary of the work going on in indexed type families, and why after all the work is finished, we'll be able to ditch functional dependencies. It seems to be an equivalently powerful way of saying equivalent things, just with a more functional style, and in ways I can understand (I still can't understand functional dependencies!).
- Ben Lippmeier - Type Inference and Optimisation for an Impure World An exploration of type inference in a language with side effects, guaranteeing optimisations are sound and permitting reordering.
- Neil Mitchell - Making Haskell Faster My talk on Supero, unfortunately I didn't manage to get the Nobench results in time, but I'll be blogging results in the next few days.
- Philippa Cowderoy - Experiences with Haskell as a person with Asperger's This talk was really unique, certainly not something that would ever have been presented at an academic venue. Philippa described some of the things in Haskell, and in the Community, that have helped her, and how she copes with Aspergers.
- Claude Heiland-Allen - Extending Pure-data with Haskell Pure-data is a program for doing music/visualisation in real time, which you can now extend with Haskell. The coolest aspect of this talk was the visualisations, showing Haskell in a very real context.
- Dan Licata - View Patterns View patterns are coming soon to GHC, as proposed for years and years. Pattern matching extensions, especially for things which have alternative representations - i.e. Sequence's and ByteString's.
- Lennart Augustsson - Fib, in Assembly Lennart generated assembly code for fib, from Haskell code. Scary stuff, showing how Haskell can both be a program, and an abstract syntax tree, with the appropriate Prelude and binding modifications.
- Duncan Coutts - Cabal Needs You Cabal is a critical infrastructure project for Haskell, but is sorely in need of more assistance. Duncan gave a brief overview of some of the features that need your help.
- Neil Mitchell - Yhc Yhc is a project with no clear goals and no overall plan - as people want to do something, they do, and it is welcomed. I tried to give some people an idea of where we are going, and what some of us want to do.
- Chris Smith - Monadic Subexpressions Another new piece of syntactic sugar that may be going into GHC are monadic subexpressions, which allow monadic actions to be placed more freely. I think this is a fantastic idea, others didn't. Chris is hoping to implement this feature, and got some good feedback from others.
- Philippa Cowderoy - Parsec as a Monad Transformer The Haskell 98 layout rule is dependent on the parse failure or success of the entire grammar. Philippa showed how this can be written in a beautiful way, simply using the new version of Parsec as a monad transformer.
My slides are online here , and we are collecting the other slides over time.
On the second day we met up, had breakfast, went rowing, then went to the pub. It was not a formal day of talks, but everyone got a chance to chat, discuss some projects and generally get to know each other.
This year Philippa was in charge, with me providing some assistance. Hopefully next year someone else would like to try and organise the event. The helpfulness of the Haskell community makes it a joy - without such a strong community an event like this would never take place.
Finally, I'd like to say thanks again to the speakers, and the people who attended. Also special thanks need to be given to Microsoft Research Cambridge, and in particular Sarah Cater, who provided a venue with catering, and could not have been more helpful!
Tuesday, July 10, 2007
Making Haskell faster than C!
I've been doing more work on my Haskell optimiser, and its going quite well. Previously I've been attempting to get some initial benchmark numbers, now I'm revisiting each of the benchmarks with a view to:
1) I've increased the default data set to 45Mb. This should give more accurate results. I've also benchmarked on a variety of computers, and found that the relative difference between processor and disk speed makes a massive difference. All the results given here are from my work machine. On my home machine Supero is up to 4 times faster than GHC!
2) It turned out that using -fvia-C meant that the gcc back end to GHC was inlining some primitive functions. I've now moved to using -fasm with ghc, which results in no inlining. I've also set appropriate definitions in the C to turn of inlining of their functions. With all these steps, no programming language does any inlining inside getchar() or isspace(). Since all programs do exactly the same number of calls to each function, this should not benefit/penalise any language, but is more consistent.
3) I've moved from using my fake version of the IO Monad, to using GHC's IO Monad. This change means that GHC no longer attempts to optimise my computations into constants, and means that future versions of GHC are guaranteed to behave in much the same way. This also has the side effect that the code should be faster (it isn't, discussed next, but it should be!)
4) With more detailed and repeatable benchmarks, I've started to look for the precise reasons why a particular benchmark performs as it does. In doing so I've noticed that GHC can place heap checks in the wrong place, sometimes fails to infer the correct strictness information and has too many stack checks. I have reported each of these issues. The benchmarks are performed with these problems present in the Supero results. As far as I am able to tell, if these three issues were solved, Supero would always obtain the same speed as C (with the same assembly code), or outperform C (in one case).
5) I discovered an issue with the words function, which I have brought to the attention of the Haskell library maintainers. The words function as currently in the libraries performs two redundant isspace tests per word detected. The fix is simple, and has been applied to the libraries Supero uses. Note that the GHC result has not had this fix applied, so could be expected to improve.
With all these modifications, it only remains to post updated benchmarks:
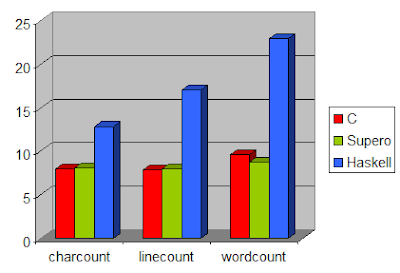
The benchmarks follow an expected pattern for character counting and line counting. The C version is minimally faster than the Supero version, 1.5% faster in both cases. The Haskell version lags substantially further behind.
The one benchmark where this is not the case is word count. In this benchmark Supero is 10% faster than C! This even includes the overheads of missed strictness, excessive heap checks and excessive stack checks. Obviously this is a surprising result, so deserves more explanation. The C code which performs word counting is:
There are essentially two states - traversing through a sequence of spaces, or traversing through a sequence of non-spaces. Depending on which state you are in, and where you are transitioning to, you may need to increment a counter. The C code maintains this state information in last_space.
However, this is not the fastest method. If that 1-bit of information was encoded in the program counter, i.e. by having different paths for being in a sequence of spaces vs non-spaces, the code can be further optimised: the last_space variable becomes redundant; the increment test can be eliminated in one branch.
To implement two tight inner loops in C, where control can bounce between the loops, is not trivial. One approach is to use goto, but this often disables some optimisations. The other approach is to have nested while loops, with a return to exit the inner loop. Either way is unpleasant, and unnatural.
Contrast this low-level hackery, with the Haskell version:
The code is specified in a high-level manner. By running this code through Supero, it automatically produces the necessary pair of tight loops, with transitions between them, using tail calls. GHC takes this code and produces directly looping code, which is able to outperform the C equivalent.
My next step is to take the Supero program, and try it on a larger range of benchmarks. I hope to tackle the nobench suite, competing against other Haskell compilers, rather than against C.
- Using much larger data sets, to increase the accuracy.
- Making sure all the tests are consistent, and that the playing field is level.
- Making the benchmarks repeatable, not relying on invariants that GHC does not promise.
- Understanding the precise results, I want to know why a particular benchmark gives the results it does.
- Improving the performance, where increased understanding enables this.
1) I've increased the default data set to 45Mb. This should give more accurate results. I've also benchmarked on a variety of computers, and found that the relative difference between processor and disk speed makes a massive difference. All the results given here are from my work machine. On my home machine Supero is up to 4 times faster than GHC!
2) It turned out that using -fvia-C meant that the gcc back end to GHC was inlining some primitive functions. I've now moved to using -fasm with ghc, which results in no inlining. I've also set appropriate definitions in the C to turn of inlining of their functions. With all these steps, no programming language does any inlining inside getchar() or isspace(). Since all programs do exactly the same number of calls to each function, this should not benefit/penalise any language, but is more consistent.
3) I've moved from using my fake version of the IO Monad, to using GHC's IO Monad. This change means that GHC no longer attempts to optimise my computations into constants, and means that future versions of GHC are guaranteed to behave in much the same way. This also has the side effect that the code should be faster (it isn't, discussed next, but it should be!)
4) With more detailed and repeatable benchmarks, I've started to look for the precise reasons why a particular benchmark performs as it does. In doing so I've noticed that GHC can place heap checks in the wrong place, sometimes fails to infer the correct strictness information and has too many stack checks. I have reported each of these issues. The benchmarks are performed with these problems present in the Supero results. As far as I am able to tell, if these three issues were solved, Supero would always obtain the same speed as C (with the same assembly code), or outperform C (in one case).
5) I discovered an issue with the words function, which I have brought to the attention of the Haskell library maintainers. The words function as currently in the libraries performs two redundant isspace tests per word detected. The fix is simple, and has been applied to the libraries Supero uses. Note that the GHC result has not had this fix applied, so could be expected to improve.
With all these modifications, it only remains to post updated benchmarks:

The benchmarks follow an expected pattern for character counting and line counting. The C version is minimally faster than the Supero version, 1.5% faster in both cases. The Haskell version lags substantially further behind.
The one benchmark where this is not the case is word count. In this benchmark Supero is 10% faster than C! This even includes the overheads of missed strictness, excessive heap checks and excessive stack checks. Obviously this is a surprising result, so deserves more explanation. The C code which performs word counting is:
int main() {
int i = 0;
int c, last_space = 1, this_space;
while ((c = getchar()) != EOF) {
this_space = isspace(c);
if (last_space && !this_space)
i++;
last_space = this_space;
}
printf("%i\n", i);
return 0;
}
There are essentially two states - traversing through a sequence of spaces, or traversing through a sequence of non-spaces. Depending on which state you are in, and where you are transitioning to, you may need to increment a counter. The C code maintains this state information in last_space.
However, this is not the fastest method. If that 1-bit of information was encoded in the program counter, i.e. by having different paths for being in a sequence of spaces vs non-spaces, the code can be further optimised: the last_space variable becomes redundant; the increment test can be eliminated in one branch.
To implement two tight inner loops in C, where control can bounce between the loops, is not trivial. One approach is to use goto, but this often disables some optimisations. The other approach is to have nested while loops, with a return to exit the inner loop. Either way is unpleasant, and unnatural.
Contrast this low-level hackery, with the Haskell version:
main = print . length . words =<< getContents
The code is specified in a high-level manner. By running this code through Supero, it automatically produces the necessary pair of tight loops, with transitions between them, using tail calls. GHC takes this code and produces directly looping code, which is able to outperform the C equivalent.
My next step is to take the Supero program, and try it on a larger range of benchmarks. I hope to tackle the nobench suite, competing against other Haskell compilers, rather than against C.
Monday, July 09, 2007
Equational Reasoning in Haskell
Update: You can actually further optimise the example in this post, which is done in my IFL 2007 Supero paper, available from my website.
Haskell is great, as it's a pure language. This means that functions don't have side effects, so can be reordered, rearranged, inlined etc. very easily. All this means that you can do reasoning in Haskell in a similar manner to that which is done in mathematics. Most Haskell programmers will exploit the reasoning properties very often, refactoring their code. Today I used equational reasoning to solve a problem I was having, which makes a nice (and simple!) introduction.
This work was all in the context of the Supero project, aiming to optimise a word counting program. I found that in the resultant code, some characters were getting tested for being a space twice (using isSpace). An additional test, and then a branch on a value which is already known, harms performance. There are two possible reasons for this duplicated test: either the input code does the test twice; or the optimiser looses some sharing. After a quick look around I decided that the latter was not occuring, so went to look at the source of words
If you are using Hugs, a simple :f words will show you this code, which I've renamed and reformatted slightly.
The key "eureka" moment is to see that s has all it's leading spaces dropped. Therefore, if s has any characters, the first must be a non-space. We then retest the first character to see if it is a space in break. This redundant test is unnecessary, but how to remove it? In Haskell equational reasoning can be used to remove the test, and serves as a proof that the code still has the same functionality.
The first step is to instantiate s in the case alternative. This is safe as the branch above has already examined the constructor, so we do not loose laziness.
Now we know that s is not a space, specifically that not (isSpace s) is true. From now on we will work only within the second case alternative. We now need the definition of break and span to proceed further:
Now we can inline break.
Now looking at span we can see that we match the xs@(x:xs') branch. Furthermore, we know from earlier that not (isSpace s) is True so we will take the first alternative. This lets us rewrite the expression as:
Now we are nearly there. We can replace word with s:ys and rest with zs using the first where binding:
Now we can rename ys to word and zs to rest.
And finally, to get us back to something very much like our original, we can fold back the span. Just as we were able to replace the left hand side of break with the right hand side, we can do the same in the other direction:
Now putting this all back into the original definition:
We now have a more efficient version of words which at every stage kept the same behaviour. I have emailed the Haskell libraries mailing list and hopefully this optimisation will be able to be applied to the standard libraries.
In reality, when I did this transformation I skipped the inlining of break and relied on what I knew about its behaviour. If a student was to do this transformation in an exam, more detail would probably be required going from (not . isSpace) in span. Either way, as your experience grows these transformations become more natural, and are a fundamental part of working with Haskell.
Haskell is great, as it's a pure language. This means that functions don't have side effects, so can be reordered, rearranged, inlined etc. very easily. All this means that you can do reasoning in Haskell in a similar manner to that which is done in mathematics. Most Haskell programmers will exploit the reasoning properties very often, refactoring their code. Today I used equational reasoning to solve a problem I was having, which makes a nice (and simple!) introduction.
This work was all in the context of the Supero project, aiming to optimise a word counting program. I found that in the resultant code, some characters were getting tested for being a space twice (using isSpace). An additional test, and then a branch on a value which is already known, harms performance. There are two possible reasons for this duplicated test: either the input code does the test twice; or the optimiser looses some sharing. After a quick look around I decided that the latter was not occuring, so went to look at the source of words
words :: String -> [String]
words string = case dropWhile isSpace string of
[] -> []
s -> word : words rest
where (word, rest) = break isSpace s
If you are using Hugs, a simple :f words will show you this code, which I've renamed and reformatted slightly.
The key "eureka" moment is to see that s has all it's leading spaces dropped. Therefore, if s has any characters, the first must be a non-space. We then retest the first character to see if it is a space in break. This redundant test is unnecessary, but how to remove it? In Haskell equational reasoning can be used to remove the test, and serves as a proof that the code still has the same functionality.
The first step is to instantiate s in the case alternative. This is safe as the branch above has already examined the constructor, so we do not loose laziness.
words string = case dropWhile isSpace s of
[] -> []
s:ss -> word : words rest
where (word, rest) = break isSpace (s:ss)
Now we know that s is not a space, specifically that not (isSpace s) is true. From now on we will work only within the second case alternative. We now need the definition of break and span to proceed further:
span, break :: (a -> Bool) -> [a] -> ([a],[a])
span p [] = ([],[])
span p xs@(x:xs')
| p x = (x:ys, zs)
| otherwise = ([],xs)
where (ys,zs) = span p xs'
break p = span (not . p)
Now we can inline break.
s:ss -> word : words rest
where (word, rest) = span (not . isSpace) (s:ss)
Now looking at span we can see that we match the xs@(x:xs') branch. Furthermore, we know from earlier that not (isSpace s) is True so we will take the first alternative. This lets us rewrite the expression as:
s:ss -> word : words rest
where (word, rest) = (s:ys, zs)
(ys,zs) = span (not . isSpace) ss
Now we are nearly there. We can replace word with s:ys and rest with zs using the first where binding:
s:ss -> (s:ys) : words zs
where (ys,zs) = span (not . isSpace) ss
Now we can rename ys to word and zs to rest.
s:ss -> (s:word) : words rest
where (word,rest) = span (not . isSpace) ss
And finally, to get us back to something very much like our original, we can fold back the span. Just as we were able to replace the left hand side of break with the right hand side, we can do the same in the other direction:
s:ss -> (s:word) : words rest
where (word,rest) = break isSpace ss
Now putting this all back into the original definition:
words :: String -> [String]
words string = case dropWhile isSpace string of
[] -> []
s:ss -> (s:word) : words rest
where (word,rest) = break isSpace ss
We now have a more efficient version of words which at every stage kept the same behaviour. I have emailed the Haskell libraries mailing list and hopefully this optimisation will be able to be applied to the standard libraries.
In reality, when I did this transformation I skipped the inlining of break and relied on what I knew about its behaviour. If a student was to do this transformation in an exam, more detail would probably be required going from (not . isSpace) in span. Either way, as your experience grows these transformations become more natural, and are a fundamental part of working with Haskell.
Friday, June 29, 2007
Functional composition
Haskell has great support for abstraction: small functions can be written which do one general thing. Haskell also has great support for composition: putting small functions together is easy.
On IRC today someone asked for a function that computes the mode of a list. This is the same as finding the most common element in a list. One simple solution is a nice display of composition of smaller abstraction functions:
And a single example:
To read the function mostCommon, it is best to read from right to help:
If asked to write the same function in Javascript (say), I would have started with a Hash table that looped counting the number of occurrences of each letter, then done a loop through this to find the maximum. The code would have been longer, and more prone to bugs.
It is easy to see that by combining functions that have already been written, tested and documented, it is possible to come up with very succinct operations.
On IRC today someone asked for a function that computes the mode of a list. This is the same as finding the most common element in a list. One simple solution is a nice display of composition of smaller abstraction functions:
mostCommon :: Ord a => [a] -> a
mostCommon = head . maximumBy (comparing length) . group . sort
And a single example:
; mostCommon "Haskell"
'l'
To read the function mostCommon, it is best to read from right to help:
- sort: put the elements in order, i.e. "Haeklls".
- group: group consecutive elemnts, i.e. ["H","a","e","k","ll","s"]. It would be entirely reasonable to have a groupSet function that did grouping of non-consecutive elements, and I often use such a function.
- maximumBy (comparing length): find the maximum value, looking only at the number of elements in each list, i.e. "ll".
- head: take a representative value from the list, i.e. 'l'.
If asked to write the same function in Javascript (say), I would have started with a Hash table that looped counting the number of occurrences of each letter, then done a loop through this to find the maximum. The code would have been longer, and more prone to bugs.
It is easy to see that by combining functions that have already been written, tested and documented, it is possible to come up with very succinct operations.
Monday, June 18, 2007
The Year 3000 problem
(Not a Haskell post, but I wish it was, I hate writing VBScript!)
When writing code for someone else, on a money per hour basis, you have to make choices that are in the clients best interest. Usually best interest is the cheapest solution that works. One example of this choice is perfection versus practicality.
When writing code for a single task, if the code meets the requirements for the task, it "works". If you have to write a function to parse a number, which launches nuclear missiles if given a negative number, and you don't give it negative numbers, then that's fine. If you spend additional time making it robust to negative numbers, you are wasting someone else's money.
If you are writing beautiful code, or a library (where people can poke the interface in unexpected ways) then handling side conditions is very important. The fewer obscure side conditions, the fewer surprises to the users. Fewer surprises means less need for documentation and fewer help emails.
As projects become larger, typically an increasing proportion of the code becomes a library which the remaining section of the program makes use of. Once this happens, it is worth going back and reconsidering and refining the interfaces to functions. Judging when a program goes from "quick hack" to "large system" is hard. The best time to go back and make this refinement is when the code is still small, but you know it will be growing shortly. Alas, this is exactly when deadlines are likely to make refactoring impossible.
So back to the title of the post, the year 3000 problem. I was writing code to search through a list for items with a particular year. The list goes back to 2005 only. I wrote a function which given a blank string returns the latest ten items, and given a year, it returns all the items which have that year. I implemented the year check using substring searching (indexOf/InStr/strstr - depending on your language). There are reasons for using substring searching rather than simple equality, but they are not relevant here. You can write this code as:
Simple enough. Now its very easy to add a facility to call the search function with the appropriate year and display the results. Now imagine that you get a change request, asking for a button to display all results. What would you do? Remember that you are looking for the solution that meets the clients needs with the least amount of work.
The answer I came up with, simply call search("2");. The code works, and will continue to work for 992 years. In the year 3000 there will no longer be a 2 in year field, and it will stop working. By then, I'm expecting to be dead, and I hope to outlive VBScript by decades, so this isn't something that will ever be a problem.
When learning to code it is important to think about the corner cases, and to deal with them appropriately - always aiming for perfection. Once you have a reasonable idea what the "perfect" solution looks like, then you need to start making concious decisions about whether perfection is the right choice. Usually it is, but sometimes you need to make compromises for the benefit of the person paying.
When writing code for someone else, on a money per hour basis, you have to make choices that are in the clients best interest. Usually best interest is the cheapest solution that works. One example of this choice is perfection versus practicality.
When writing code for a single task, if the code meets the requirements for the task, it "works". If you have to write a function to parse a number, which launches nuclear missiles if given a negative number, and you don't give it negative numbers, then that's fine. If you spend additional time making it robust to negative numbers, you are wasting someone else's money.
If you are writing beautiful code, or a library (where people can poke the interface in unexpected ways) then handling side conditions is very important. The fewer obscure side conditions, the fewer surprises to the users. Fewer surprises means less need for documentation and fewer help emails.
As projects become larger, typically an increasing proportion of the code becomes a library which the remaining section of the program makes use of. Once this happens, it is worth going back and reconsidering and refining the interfaces to functions. Judging when a program goes from "quick hack" to "large system" is hard. The best time to go back and make this refinement is when the code is still small, but you know it will be growing shortly. Alas, this is exactly when deadlines are likely to make refactoring impossible.
So back to the title of the post, the year 3000 problem. I was writing code to search through a list for items with a particular year. The list goes back to 2005 only. I wrote a function which given a blank string returns the latest ten items, and given a year, it returns all the items which have that year. I implemented the year check using substring searching (indexOf/InStr/strstr - depending on your language). There are reasons for using substring searching rather than simple equality, but they are not relevant here. You can write this code as:
function search(year)
{
var items = complicated_code_here();
for (var i in items)
{
if ((year == "" && i < 10) ||
(items[i].year.indexOf(year) != -1))
display(items[i]);
}
}
Simple enough. Now its very easy to add a facility to call the search function with the appropriate year and display the results. Now imagine that you get a change request, asking for a button to display all results. What would you do? Remember that you are looking for the solution that meets the clients needs with the least amount of work.
The answer I came up with, simply call search("2");. The code works, and will continue to work for 992 years. In the year 3000 there will no longer be a 2 in year field, and it will stop working. By then, I'm expecting to be dead, and I hope to outlive VBScript by decades, so this isn't something that will ever be a problem.
When learning to code it is important to think about the corner cases, and to deal with them appropriately - always aiming for perfection. Once you have a reasonable idea what the "perfect" solution looks like, then you need to start making concious decisions about whether perfection is the right choice. Usually it is, but sometimes you need to make compromises for the benefit of the person paying.
Friday, June 15, 2007
Boilerplate considered harmful (Uniplate edition!)
I've just released my Uniplate library, which hopes to remove the boilerplate from Haskell programs. I try to keep my PhD research as practically orientated as I can, but often research things start off as proof of concept and get refined into something more practically usable over time. Uniplate is different - its the one part of my PhD that should be useful to almost everyone, and is useful and polished right now.
I've been working on Uniplate (or Play, as it was originally called) for about two years now. Uniplate did not start off as a project to remove boilerplate, but in my work on Catch I found various patterns kept cropping up. I started to think about abstracting them out - first in a very chaotic manner - then as time progressed I refined the ideas until they hung together much more convincingly. I've used Uniplate in Catch (well over 100 times!), in Yhc.Core (support is built into the library), and most recently in Hoogle. In addition, a few other people have picked up Uniplate (Eric Mertens and Matt Naylor), and with very little time were quite fluent in the use of the library.
I previously posted a bit about how you could use Scrap Your Boilerplate (SYB) to remove boilerplate from Haskell. I'm now going to recap that post, but giving the examples using Uniplate as well. Hopefully this will start to encourage people to make use of Uniplate - the results can be very effective. Recently Matt ported one of his projects, and some functions went from 20 lines of complicated code to 3 lines of simple code - revealing some bugs in the original definition in the process!
A Data Structure
Before showing some operations, I'm going to first introduce a data structure on which we can imagine operations are performed. Here is a data type that looks like an imperative programming language:
We define the data type as normal, adding deriving for Data and Typeable - the two key SYB types. We also add an import of Data.Generics and a flag, just to get the GHC machinery working for the derivings. Finally, we add an import of Data.Generics.PlateData - which says that we want to automatically derive the necessary Uniplate instances, and use the Uniplate operations.
Queries
So lets imagine you have to get a list of all literals. In SYB this is easy:
Wow, easy! But we can make it even easier with Uniplate:
Both functions will operate on anything which has a Data instance, so you can run it on an Expr, Stmt, [Stmt], [Either Stmt Expr] - the choice is yours. The Uniplate function universeBi simply gives you a list of all the Expr types in x, from which you can pick the Lit's using a nice list comprehension.
Transformations
Now lets negate all the literals, in SYB we have:
Again, its pretty easy. We can also do something very similar in Uniplate:
The only difference is a mkT.
Advantages of Uniplate
There are a number of advantages:
What Uniplate is NOT
The SYB library has gone much further than queries and transformations - they provide what amounts to runtime reflection and an incredible level of power. They also offer type generic programming, extensible functions and much more besides. Uniplate does not attempt to offer anything beyond standard traversals.
It is also important to point out that SYB is strictly more powerful than Uniplate. You can implement Uniplate on top of SYB, but cannot implement SYB on top of Uniplate. I would still encourage everyone to read up on SYB - it can be complex to pull of some of the more advanced tricks, but the power can take Haskell to whole new levels.
Conclusion
I hope that people will take a look at Uniplate, and see if it can meet their needs - in any project where a data type is defined and operated over it can probably be of benefit. The code reductions that can be made with Uniplate (or SYB) are substantial, and can hopefully promote the concise declarative style which Haskell was designed for.
I've been working on Uniplate (or Play, as it was originally called) for about two years now. Uniplate did not start off as a project to remove boilerplate, but in my work on Catch I found various patterns kept cropping up. I started to think about abstracting them out - first in a very chaotic manner - then as time progressed I refined the ideas until they hung together much more convincingly. I've used Uniplate in Catch (well over 100 times!), in Yhc.Core (support is built into the library), and most recently in Hoogle. In addition, a few other people have picked up Uniplate (Eric Mertens and Matt Naylor), and with very little time were quite fluent in the use of the library.
I previously posted a bit about how you could use Scrap Your Boilerplate (SYB) to remove boilerplate from Haskell. I'm now going to recap that post, but giving the examples using Uniplate as well. Hopefully this will start to encourage people to make use of Uniplate - the results can be very effective. Recently Matt ported one of his projects, and some functions went from 20 lines of complicated code to 3 lines of simple code - revealing some bugs in the original definition in the process!
A Data Structure
Before showing some operations, I'm going to first introduce a data structure on which we can imagine operations are performed. Here is a data type that looks like an imperative programming language:
{-# OPTIONS_GHC -fglasgow-exts #-}
import Data.Generics
import Data.Generics.PlateData
data Expr = Var String
| Lit Int
| Call String [Expr]
deriving (Data, Typeable)
data Stmt = While Expr [Stmt]
| Assign String Expr
| Sequence [Stmt]
deriving (Data,Typeable)
We define the data type as normal, adding deriving for Data and Typeable - the two key SYB types. We also add an import of Data.Generics and a flag, just to get the GHC machinery working for the derivings. Finally, we add an import of Data.Generics.PlateData - which says that we want to automatically derive the necessary Uniplate instances, and use the Uniplate operations.
Queries
So lets imagine you have to get a list of all literals. In SYB this is easy:
extractLits :: Data a => a -> [Int]
extractLits = everything (++) ([] `mkQ` f)
where f (Lit x) = [x]
f _ = []
Wow, easy! But we can make it even easier with Uniplate:
extractLits :: Data a => a -> [Int]
extractLits x = [y | Lit y <- universeBi x]
Both functions will operate on anything which has a Data instance, so you can run it on an Expr, Stmt, [Stmt], [Either Stmt Expr] - the choice is yours. The Uniplate function universeBi simply gives you a list of all the Expr types in x, from which you can pick the Lit's using a nice list comprehension.
Transformations
Now lets negate all the literals, in SYB we have:
negLit (Lit x) = Lit (negate x)
negLit x = x
negateLits :: Data a => a -> a
negateLits = everywhere (mkT negLit)
Again, its pretty easy. We can also do something very similar in Uniplate:
negateLits :: Data a => a -> a
negateLits = transformBi negLit
The only difference is a mkT.
Advantages of Uniplate
There are a number of advantages:
- Compatability - the above code will work only in GHC, but if we modify the instance declaration to remove deriving(Data,Typeable) and replace it with an explicit instance (generated by Derive, if you wish), then the Uniplate code will work perfectly happy in Hugs. The Uniplate library also provides substantial Haskell 98 compatibility.
- Built in compiler support in GHC to the same level as SYB - piggy-backing off the SYB support.
- Usually produces shorter code - especially for queries.
- A range of traversals not in SYB (although SYB could add them - and I believe should)
- Higher performance - about 30% faster in the above examples, up to 80% faster if you are will to write different instances.
What Uniplate is NOT
The SYB library has gone much further than queries and transformations - they provide what amounts to runtime reflection and an incredible level of power. They also offer type generic programming, extensible functions and much more besides. Uniplate does not attempt to offer anything beyond standard traversals.
It is also important to point out that SYB is strictly more powerful than Uniplate. You can implement Uniplate on top of SYB, but cannot implement SYB on top of Uniplate. I would still encourage everyone to read up on SYB - it can be complex to pull of some of the more advanced tricks, but the power can take Haskell to whole new levels.
Conclusion
I hope that people will take a look at Uniplate, and see if it can meet their needs - in any project where a data type is defined and operated over it can probably be of benefit. The code reductions that can be made with Uniplate (or SYB) are substantial, and can hopefully promote the concise declarative style which Haskell was designed for.
Friday, June 08, 2007
The Test Monad
Lots of people have written clever things about writing monads - their mathematical structure, properties etc. I wrote a Test Monad for my FilePath library, which I've since refined for Hoogle. The inspiration for this comes from Lennart Augustsson, who gave a talk at fun in the afternoon on ways to abuse Haskell syntax for other purposes.
For the testing of the parser in Hoogle, I want to write a list of strings, versus the data structures they should produce:
In Haskell, the most syntactically pleasant way of writing a list of things is using do notation in a monad. This means that each (===) operation should be in a monad, and the (>>) bind operation should execute one test, then the next. We also need some way of "executing" all these tests. Fortunately this is all quite easy:
The basic type is Test, which has only one value, being Pass. To represent failure, simply call error, which is failure in all Haskell programs and allows you to give a useful error message. The helper function pass is provided to pin down the type, so you don't get ambiguity errors. The Monad instance simply ensures that all the tests are evaluated, so that if any crash then the whole program will crash. The Show instance demands that all the tests passed, then gives a message stating that.
We can then layer our own test combinators on top, for example for parsec:
This parseTest function takes a parsec parser, an input and an output. If the parse fails, or doesn't produce the correct answer, an error is raised. If the test passes, then the function calls pass. It's then simple enough to define each test set as:
Here (===) is defined differently for each do block. By evaluating one of these test blocks in an interpreter, the show method will automatically be called, executing all the tests.
I've found this "monad" lets you express tests very succinctly, and execute them easily. I moved to this test format from stand-alone files listing sample inputs and expected results, and its proved much easier to maintain and more useful.
For the testing of the parser in Hoogle, I want to write a list of strings, versus the data structures they should produce:
"/info" === defaultQuery{flags = [Flag "info" ""]}
"/count=10" === defaultQuery{flags = [Flag "count" "10"]}
In Haskell, the most syntactically pleasant way of writing a list of things is using do notation in a monad. This means that each (===) operation should be in a monad, and the (>>) bind operation should execute one test, then the next. We also need some way of "executing" all these tests. Fortunately this is all quite easy:
data Test a = Pass
instance Monad Test where
a >> b = a `seq` b
instance Show (Test a) where
show x = x `seq` "All tests passed"
pass :: Test ()
pass = Pass
The basic type is Test, which has only one value, being Pass. To represent failure, simply call error, which is failure in all Haskell programs and allows you to give a useful error message. The helper function pass is provided to pin down the type, so you don't get ambiguity errors. The Monad instance simply ensures that all the tests are evaluated, so that if any crash then the whole program will crash. The Show instance demands that all the tests passed, then gives a message stating that.
We can then layer our own test combinators on top, for example for parsec:
parseTest f input output =
case f input of
Left x -> err "Parse failed" (show x)
Right x -> if x == output then pass else
err "Parse not equal" (show x)
where
err pre post = error $ pre ++ ":\n " ++
input ++ "\n " ++
show output ++ "\n " ++
post
This parseTest function takes a parsec parser, an input and an output. If the parse fails, or doesn't produce the correct answer, an error is raised. If the test passes, then the function calls pass. It's then simple enough to define each test set as:
parse_Query = do
let (===) = parseTest parseQuery
Here (===) is defined differently for each do block. By evaluating one of these test blocks in an interpreter, the show method will automatically be called, executing all the tests.
I've found this "monad" lets you express tests very succinctly, and execute them easily. I moved to this test format from stand-alone files listing sample inputs and expected results, and its proved much easier to maintain and more useful.
Releasing Catch
Finally, after over two years of work, I've released Catch! I recommend people use the tarball on hackage. The manual has all the necessary installation instructions. To make installation easier, rather than following the Cabal route of releasing lots of dependent libraries, I've take the transitive closure and shoved them into one .cabal file.
I've had the release prepared for some time, but was waiting until after the ICFP reviewing had finished (I got rejected :( ), to make a release, because of their anonymity requirements. Now that's all finished, I invite everyone to download and try Catch.
The final release is only 2862 lines of code, which doesn't seem like much for two years worth of work. The actual analysis is only 864 lines long, of which about half the lines are blank, and one or two are comments. If you include all the Yhc.Core libraries, my proposition library, my boilerplate removal library (all of which were developed to make Catch possible), you end up with just under 8000 lines of code. Still substantially shorter than my A-level computing project, which I wrote in C++.
Catch has seen a bit of real world use, particular in HsColour, where it found two crashing bugs, and XMonad where it influenced the design of the central API. I'm starting to routinely Catch check all the libraries I release, which is a good sign. One of the things that restricts Catch from being more widely used is the lack of Haskell 98 code in general use - Catch is in no way limited to Haskell 98, but Yhc which Catch uses as a front end is. Hopefully the Haskell' standard will encourage more people to code to a recognised standard, and increase the utility of source code analysis/manipulation tools.

If anyone does try out Catch, and has any comments, please do email me (ndmitchell @at@ gmail .dot. com). If you take the time to check your program with Catch you are welcome to use the "Checked by Catch logo".
I've had the release prepared for some time, but was waiting until after the ICFP reviewing had finished (I got rejected :( ), to make a release, because of their anonymity requirements. Now that's all finished, I invite everyone to download and try Catch.
The final release is only 2862 lines of code, which doesn't seem like much for two years worth of work. The actual analysis is only 864 lines long, of which about half the lines are blank, and one or two are comments. If you include all the Yhc.Core libraries, my proposition library, my boilerplate removal library (all of which were developed to make Catch possible), you end up with just under 8000 lines of code. Still substantially shorter than my A-level computing project, which I wrote in C++.
Catch has seen a bit of real world use, particular in HsColour, where it found two crashing bugs, and XMonad where it influenced the design of the central API. I'm starting to routinely Catch check all the libraries I release, which is a good sign. One of the things that restricts Catch from being more widely used is the lack of Haskell 98 code in general use - Catch is in no way limited to Haskell 98, but Yhc which Catch uses as a front end is. Hopefully the Haskell' standard will encourage more people to code to a recognised standard, and increase the utility of source code analysis/manipulation tools.
If anyone does try out Catch, and has any comments, please do email me (ndmitchell @at@ gmail .dot. com). If you take the time to check your program with Catch you are welcome to use the "Checked by Catch logo".
Wednesday, May 23, 2007
Preconditions on XMonad
{- ICFP referees look away now -}
I've proved that the central XMonad StackSet module is safe on several occasions, as the code keeps evolving. Each time I take the source code, run Catch on it, and send an email back to the XMonad list giving the results. So far only one other person (Spencer Janssen) has taken the time to download and install Catch and run the tests to validate my result. The reason for this is that building Catch is slightly tricky, due to the Yhc and Yhc.Core dependencies. I'm working on putting together a proper release for Hackage, expect that within a month - all the code works, its just the packaging and user interface thats lacking.
The other day dons asked me how he could "get an idea" of what Catch is doing. If you blindly accept a formal proof, its hard to get a feel of whether its correct, or if you are proving what you expect. The detailed answer is going to appear in my thesis (and hopefully as a paper beforehand), but I thought it may help to give a very light overview of what thoughts go through Catch.
In Principle
The concept behind Catch is that each function has a precondition that must hold in order for the function to execute without error. If a function f calls a function g which has a precondition, then the precondition for f must guarantee that the precondition to g holds. If you set this up so that error has the precondition False, then you have a pattern match checker.
The second concept is that given a postcondition on a function, you can transform that to a precondition on the arguments to the function. If there is a requirement that the result of f x y meets a certain condition, then this can be expressed as conditions on the variables x and y.
Before all this machinery can be put into action, it is first necessary to perform many transformations on the source code - filling in default pattern matches, doing simplifications, removing higher-order functions and abstracting some library functions. All these transformations are performed automatically, and are intended to set up the Catch machinery to do the best job it can.
In Reality
As it happens, most of the pattern matches that are checked in XMonad are relatively trivial - and do not push the power of Catch to its full potential. A few are slightly more complex, and one of these is focusLeft (XMonad code evolves very fast, so this may not be the current darcs version!):
Catch identifies two separate potential pattern match errors in this statement. Firstly the lambda expression passed as the second argument to modify is potentially unsafe - as it does not mention the Empty constructor. A quick look at the modify function shows that by this stage the value must be a Node. The way Catch solves this is by transforming the code, bringing the two pices of code together. Once the case expression within modify is merged with the one in the lambda, pattern match safety is a simple transformation of elimating redundant alternatives.
The second potential error is in the where statement. If reverse rs is empty then the pattern will not match. This is a perfect example of the postconditions in action, the generated postcondition is that reverse rs must be a (:) constructed value. Using the machinery in Catch, this condition is transformed into the condition that rs must be a (:) value. Looking at the alternatives, Catch can see this is always the case, and declares the pattern safe.
In order to prove the entire module, Catch requires 23 properties, and 12 preconditions. The process takes 1.16 seconds are requires 1521.05 Kb of memory.
In Conclusion
Catch is an automated tool - no user annotations are required - which means that some people may feel excluded from its computational thoughts. If a user does wish to gain confidence in the Catch checking process, a full log is produced of all the preconditions and postconditions required, but it isn't bedtime reading. Hopefully this post will let people get an idea for how Catch works at a higher level.
I am very glad that Catch is an automated tool. XMonad is a fast changing code base, with many contributors. In a manual system, requiring proofs to remain in lockstep with the code, the pace of progress would be slowed dramatically. Hopefully Catch can give cheap verification, and therefore verification which can be of practical user to non-experts.
I've proved that the central XMonad StackSet module is safe on several occasions, as the code keeps evolving. Each time I take the source code, run Catch on it, and send an email back to the XMonad list giving the results. So far only one other person (Spencer Janssen) has taken the time to download and install Catch and run the tests to validate my result. The reason for this is that building Catch is slightly tricky, due to the Yhc and Yhc.Core dependencies. I'm working on putting together a proper release for Hackage, expect that within a month - all the code works, its just the packaging and user interface thats lacking.
The other day dons asked me how he could "get an idea" of what Catch is doing. If you blindly accept a formal proof, its hard to get a feel of whether its correct, or if you are proving what you expect. The detailed answer is going to appear in my thesis (and hopefully as a paper beforehand), but I thought it may help to give a very light overview of what thoughts go through Catch.
In Principle
The concept behind Catch is that each function has a precondition that must hold in order for the function to execute without error. If a function f calls a function g which has a precondition, then the precondition for f must guarantee that the precondition to g holds. If you set this up so that error has the precondition False, then you have a pattern match checker.
The second concept is that given a postcondition on a function, you can transform that to a precondition on the arguments to the function. If there is a requirement that the result of f x y meets a certain condition, then this can be expressed as conditions on the variables x and y.
Before all this machinery can be put into action, it is first necessary to perform many transformations on the source code - filling in default pattern matches, doing simplifications, removing higher-order functions and abstracting some library functions. All these transformations are performed automatically, and are intended to set up the Catch machinery to do the best job it can.
In Reality
As it happens, most of the pattern matches that are checked in XMonad are relatively trivial - and do not push the power of Catch to its full potential. A few are slightly more complex, and one of these is focusLeft (XMonad code evolves very fast, so this may not be the current darcs version!):
focusLeft = modify Empty $ \c -> case c of
Node _ _ [] [] -> c
Node m t (l:ls) rs -> Node m l ls (t:rs)
Node m t [] rs -> Node m x xs [t] where (x:xs) = reverse rs -- wrap
Catch identifies two separate potential pattern match errors in this statement. Firstly the lambda expression passed as the second argument to modify is potentially unsafe - as it does not mention the Empty constructor. A quick look at the modify function shows that by this stage the value must be a Node. The way Catch solves this is by transforming the code, bringing the two pices of code together. Once the case expression within modify is merged with the one in the lambda, pattern match safety is a simple transformation of elimating redundant alternatives.
The second potential error is in the where statement. If reverse rs is empty then the pattern will not match. This is a perfect example of the postconditions in action, the generated postcondition is that reverse rs must be a (:) constructed value. Using the machinery in Catch, this condition is transformed into the condition that rs must be a (:) value. Looking at the alternatives, Catch can see this is always the case, and declares the pattern safe.
In order to prove the entire module, Catch requires 23 properties, and 12 preconditions. The process takes 1.16 seconds are requires 1521.05 Kb of memory.
In Conclusion
Catch is an automated tool - no user annotations are required - which means that some people may feel excluded from its computational thoughts. If a user does wish to gain confidence in the Catch checking process, a full log is produced of all the preconditions and postconditions required, but it isn't bedtime reading. Hopefully this post will let people get an idea for how Catch works at a higher level.
I am very glad that Catch is an automated tool. XMonad is a fast changing code base, with many contributors. In a manual system, requiring proofs to remain in lockstep with the code, the pace of progress would be slowed dramatically. Hopefully Catch can give cheap verification, and therefore verification which can be of practical user to non-experts.
#if NOCPP
I use both GHC and Hugs for my development work. I primarily work with WinHugs for development, then move on to GHC for deployment. Unfortunately one of the things that WinHugs doesn't do very well is CPP support, it can only be turned on or off for all files, and requires multiple passes and slows things down. So what you really need is some way of defining code which executes in the presence and absence of CPP - so you can customise correctly.
It's not too hard to make this work, but it can be a bit fiddly to come up with the correct constructs. The easier one is to exclude code from the CPP, which can be easily accomplished with #if 0:
If the CPP is on, the closing comment and the cppOff definition will be ignored. The other direction, having code only available when CPP is on, requires the nested comments available in Haskell:
The non-cpp contains an extra open comment, which nests the comments, and leaves the definition invisible.
With these two fragments, you can customise your Haskell code so that it performs differently on systems with and without a CPP, remaining valid Haskell on sytems with no knowledge of CPP.
It's not too hard to make this work, but it can be a bit fiddly to come up with the correct constructs. The easier one is to exclude code from the CPP, which can be easily accomplished with #if 0:
{-
#if 0
-}
cppOff = True
{-
#endif
-}
If the CPP is on, the closing comment and the cppOff definition will be ignored. The other direction, having code only available when CPP is on, requires the nested comments available in Haskell:
{-
#if 0
{-
#endif
-}
cppOn = 1
{-
#if 0
-}
#endif
-}
The non-cpp contains an extra open comment, which nests the comments, and leaves the definition invisible.
With these two fragments, you can customise your Haskell code so that it performs differently on systems with and without a CPP, remaining valid Haskell on sytems with no knowledge of CPP.
Friday, May 18, 2007
47% faster than GHC*
* This is building on from last time. In particular, that means that all the same disclaimers apply.
Having done "wc -c" as the previous benchmark, the next thing to look at is "wc -l" - line counting. A line is defined as being a sequence of non-newline characters, optionally ending with a newline. This means that "test" has 1 line, "test\n" has 1 line, "test\ntest" has 2 lines. Its trivial to express this in Haskell:
The Haskell code uses the same getContents as before, but the C code needed more changes:
The C code is quite hard to write. In fact, this code is the original version I wrote - with an accidental mistake. Rest assured that I benchmarked with the correct code, but see if you can spot the mistake.
As in the previous example, I've demanded that all implementations use getchar at their heart, to make everything a fair comparison. The benchmark was then line counting on the same 35Mb file as previously:
And the numbers: C=4.969, Supero=5.063, GHC=9.533. This time the difference between C and Supero is a mere 2%. However the difference between Supero and GHC has grown considerably! The reason for this is an advanced optimisation that has managed to remove all the intermediate lists. In a normal Haskell program, getContents would build a list of characters, lines would take that list, and build a list of strings, then length would take that list and consume it. With my optimisation, no intermediate lists are created at all.
While in the previous benchmark it was easy to examine and understand the generated GHC Core, for this one it is much harder. The benchmark has ended up using a recursive group of functions, none of which use unboxed numbers. For this reason, I suspect that the benchmark could be improved further for Supero. Once again, credit needs to be given to GHC for the results - it is clearly doing some clever things.
This benchmark is slightly more interesting than the previous one, but is still a bit of a micro-benchmark - not following a real program. My next task is to probably move on to "wc -w" to complete then set, then a real benchmark suite such as nobench. I hope that this demonstrates that Haskell can be beautiful, pure, and match C for speed in some cases.
Having done "wc -c" as the previous benchmark, the next thing to look at is "wc -l" - line counting. A line is defined as being a sequence of non-newline characters, optionally ending with a newline. This means that "test" has 1 line, "test\n" has 1 line, "test\ntest" has 2 lines. Its trivial to express this in Haskell:
print . length . lines =<< getContents
The Haskell code uses the same getContents as before, but the C code needed more changes:
#include "stdio.h"
int main()
{
int i = 0;
int last = 0;
while (last = getchar() != EOF) {
if (last == '\n')
i++;
}
if (last == '\n')
i--;
printf("%i\n", i);
return 0;
}
The C code is quite hard to write. In fact, this code is the original version I wrote - with an accidental mistake. Rest assured that I benchmarked with the correct code, but see if you can spot the mistake.
As in the previous example, I've demanded that all implementations use getchar at their heart, to make everything a fair comparison. The benchmark was then line counting on the same 35Mb file as previously:

And the numbers: C=4.969, Supero=5.063, GHC=9.533. This time the difference between C and Supero is a mere 2%. However the difference between Supero and GHC has grown considerably! The reason for this is an advanced optimisation that has managed to remove all the intermediate lists. In a normal Haskell program, getContents would build a list of characters, lines would take that list, and build a list of strings, then length would take that list and consume it. With my optimisation, no intermediate lists are created at all.
While in the previous benchmark it was easy to examine and understand the generated GHC Core, for this one it is much harder. The benchmark has ended up using a recursive group of functions, none of which use unboxed numbers. For this reason, I suspect that the benchmark could be improved further for Supero. Once again, credit needs to be given to GHC for the results - it is clearly doing some clever things.
This benchmark is slightly more interesting than the previous one, but is still a bit of a micro-benchmark - not following a real program. My next task is to probably move on to "wc -w" to complete then set, then a real benchmark suite such as nobench. I hope that this demonstrates that Haskell can be beautiful, pure, and match C for speed in some cases.
Wednesday, May 16, 2007
13% faster than GHC*
* As usual, I'm going to qualify this with "on one particular benchmark, on one particular machine, with one particular set of following wind".
I've been working on optimisation techniques for the last week, as one chapter of my PhD is likely to be on that topic. The approach I'm using is to take Yhc.Core, optimise it at the Core level, then spit out GHC Haskell which can then be compiled. The optimisation technique I've been working on can best be described as "deforestation on steroids" - its entirely automatic (no notion of special named functions like in foldr/build etc) and isn't too expensive.
The particular benchmark I've been working on is "print . length =<< getContents" or "wc -c". In order to make it a fair comparison, I require that all implementationsmust use the C getchar function at their heart for getting the next character - not allowing any buffering or block reads. This is actually a substantial benefit for C, since in Haskell things like clever buffering can be done automatically (and GHC does them!) - but it does result in a test which is purely on computational crunch.
Writing this benchmark in C is quite easy:
Writing in Haskell, forcing the use of getchar, is a little bit more tricky:
I then benchmarked the C on -O3, versus the Haskell going through my optimiser, and going through GHC on -O2. The benchmark was counting the characters in a 35Mb file, run repeatedly, as usual:
 The actual numbers are C=4.830, Supero=5.064, GHC=5.705. This makes Supero 5% slower than C, and GHC 18% slower than C. The reason that Supero is faster is because its managed to deforest the length/getContents pair. The inner loop in Supero allocates no data at all, compared to the GHC one which does. Supero allocates 11,092 bytes in the heap, GHC allocates 1,104,515,888.
The actual numbers are C=4.830, Supero=5.064, GHC=5.705. This makes Supero 5% slower than C, and GHC 18% slower than C. The reason that Supero is faster is because its managed to deforest the length/getContents pair. The inner loop in Supero allocates no data at all, compared to the GHC one which does. Supero allocates 11,092 bytes in the heap, GHC allocates 1,104,515,888.
This benchmark is not a particularly good one - the task is simple, the computation is minimal and most expense is spent inside the getchar function. It is however a good place to start, and shows that Haskell can get very close to C speeds - even using standard type String = [Char] processing. Supero has made global optimisations that GHC was unable to, and does not have any techniques with which it could acheive the same results. GHC has then taken the Supero output and automatically identified strictness, performed unboxing/inlining, and done lots of other useful low-level optimisations.
I'm going to move on to "wc -l" next, and hopefully onto the nobench suite. The techniques used in Supero are all general, and I hope that as the complexity of the problem increases, the payoff will do so too.
I've been working on optimisation techniques for the last week, as one chapter of my PhD is likely to be on that topic. The approach I'm using is to take Yhc.Core, optimise it at the Core level, then spit out GHC Haskell which can then be compiled. The optimisation technique I've been working on can best be described as "deforestation on steroids" - its entirely automatic (no notion of special named functions like in foldr/build etc) and isn't too expensive.
The particular benchmark I've been working on is "print . length =<< getContents" or "wc -c". In order to make it a fair comparison, I require that all implementations
Writing this benchmark in C is quite easy:
#include "stdio.h"
int main()
{
int i = 0;
while (getchar() != EOF)
i++;
printf("%i\n", i);
return 0;
}
Writing in Haskell, forcing the use of getchar, is a little bit more tricky:
{-# OPTIONS_GHC -fffi #-}
import Foreign.C.Types
import System.IO
import System.IO.Unsafe
foreign import ccall unsafe "stdio.h getchar" getchar :: IO CInt
main = print . length =<< getContents2
getContents2 :: IO String
getContents2 = do
c <- getchar
if c == (-1) then return [] else do
cs <- unsafeInterleaveIO getContents2
return (toEnum (fromIntegral c) : cs)
I then benchmarked the C on -O3, versus the Haskell going through my optimiser, and going through GHC on -O2. The benchmark was counting the characters in a 35Mb file, run repeatedly, as usual:
 The actual numbers are C=4.830, Supero=5.064, GHC=5.705. This makes Supero 5% slower than C, and GHC 18% slower than C. The reason that Supero is faster is because its managed to deforest the length/getContents pair. The inner loop in Supero allocates no data at all, compared to the GHC one which does. Supero allocates 11,092 bytes in the heap, GHC allocates 1,104,515,888.
The actual numbers are C=4.830, Supero=5.064, GHC=5.705. This makes Supero 5% slower than C, and GHC 18% slower than C. The reason that Supero is faster is because its managed to deforest the length/getContents pair. The inner loop in Supero allocates no data at all, compared to the GHC one which does. Supero allocates 11,092 bytes in the heap, GHC allocates 1,104,515,888.This benchmark is not a particularly good one - the task is simple, the computation is minimal and most expense is spent inside the getchar function. It is however a good place to start, and shows that Haskell can get very close to C speeds - even using standard type String = [Char] processing. Supero has made global optimisations that GHC was unable to, and does not have any techniques with which it could acheive the same results. GHC has then taken the Supero output and automatically identified strictness, performed unboxing/inlining, and done lots of other useful low-level optimisations.
I'm going to move on to "wc -l" next, and hopefully onto the nobench suite. The techniques used in Supero are all general, and I hope that as the complexity of the problem increases, the payoff will do so too.
Wednesday, May 09, 2007
Does XMonad crash?
{- ICFP referees look away now. -}
Dons recently asked me to look over the StackSet.hs module of XMonad, checking for pattern-match errors, using my Catch tool. This module is the main API for XMonad, and having a proof of pattern-match safety would be a nice result. I performed an initial check of the library, including introducing the necessary infrastructure to allow Catch to execute, then sent them the required patches. After I had given them the Catch tool and the initial results, sjanssen picked up the results and went on to modify the code further - with the end result that now StackSet will never crash with a pattern-match error.
I'm not going to cover the changes that XMonad required to achieve safety - that is a story that sjanssen is much better equiped to tell. What I am going to describe is the process I followed to get to the initial results.
Step 1: Download Catch, Yhc and XMonad
Catch can be obtained from http://www-users.cs.york.ac.uk/~ndm/catch/ - however a word of warning - it is an involved installation procedure. In the next few months I hope to make Catch use Cabal, and then ordinary users will be able to easily install Catch.
Yhc can be obtained from http://www.haskell.org/haskellwiki/Yhc
XMonad can be obtained from http://www.xmonad.org/
Step 2: Make sure StackSet.hs compiles with Yhc
Initially StackSet used pattern guards, one small patch and these were removed. There was also a small issue with defaulting and Yhc, which I was able to paper over with another small patch. With these two minor changes Yhc was able to compile StackSet.
Step 3: Write a test for StackSet
The test for StackSet is based on the Catch library testing framework, and is all available at http://darcs.haskell.org/~sjanssen/xmonad/tests/Catch.hs
The basic idea is to write a main function which is all the functions under test:
--------------------------------------------------------
module Catch where
import StackSet
main = screen ||| peekStack ||| index ||| ...
--------------------------------------------------------
Catch takes care of all the remaining details. The ||| operator says to check that under all circumstances the function will not crash with a pattern-match error. The module is actually slightly more involved, but this is all detail which Catch will shortly hide into a library.
A future intention is to have a tool which automatically generates such a module from a library. This then allows the person performing the checking to simply point at a library, with no additional infrastructure.
Step 4: Test using Catch
This step is the first time we actually invoke Catch - and its as simple as a single line:
> catch Catch.hs -errors -partial
And thats it, now Catch gives you all the necessary information to start fixing your code. I emailed a summary of the results as given by Catch to the XMonad list: http://www.haskell.org/pipermail/xmonad/2007-May/000196.html
At this point I hopped on IRC, and in discussions with sjannsen talked him through installing Catch and the necessary dependencies. Once he had this installed, he was able to modify the StackSet API and implementation to guarantee that no pattern match errors are raised. After all of this, now running Catch over the test script gives success.
A lesson to take away
There were only two sticking points in running Catch over XMonad. The first was that Yhc can't always compile the code, and may require slight tweaks to be made. There are two solutions to fixing this, we can either fix Yhc, or I can make Catch use GHC Core. The GHC Core solution shouldn't be too much work, once GHC has a library for external Core.
The second sticking point is that installing Catch is a lot harder than it should be. A little bit of Cabal magic and a proper release should squash these problems easily.
So what lessons did I learn? Perhaps the thing that surprised me most is how easily someone else was able to get to grips with the Catch tool. This gives me a strong sense of hope that average users may be able to employ the Catch tool upon their programs, either in this version of a future version.
Dons recently asked me to look over the StackSet.hs module of XMonad, checking for pattern-match errors, using my Catch tool. This module is the main API for XMonad, and having a proof of pattern-match safety would be a nice result. I performed an initial check of the library, including introducing the necessary infrastructure to allow Catch to execute, then sent them the required patches. After I had given them the Catch tool and the initial results, sjanssen picked up the results and went on to modify the code further - with the end result that now StackSet will never crash with a pattern-match error.
I'm not going to cover the changes that XMonad required to achieve safety - that is a story that sjanssen is much better equiped to tell. What I am going to describe is the process I followed to get to the initial results.
Step 1: Download Catch, Yhc and XMonad
Catch can be obtained from http://www-users.cs.york.ac.uk/~ndm/catch/ - however a word of warning - it is an involved installation procedure. In the next few months I hope to make Catch use Cabal, and then ordinary users will be able to easily install Catch.
Yhc can be obtained from http://www.haskell.org/haskellwiki/Yhc
XMonad can be obtained from http://www.xmonad.org/
Step 2: Make sure StackSet.hs compiles with Yhc
Initially StackSet used pattern guards, one small patch and these were removed. There was also a small issue with defaulting and Yhc, which I was able to paper over with another small patch. With these two minor changes Yhc was able to compile StackSet.
Step 3: Write a test for StackSet
The test for StackSet is based on the Catch library testing framework, and is all available at http://darcs.haskell.org/~sjanssen/xmonad/tests/Catch.hs
The basic idea is to write a main function which is all the functions under test:
--------------------------------------------------------
module Catch where
import StackSet
main = screen ||| peekStack ||| index ||| ...
--------------------------------------------------------
Catch takes care of all the remaining details. The ||| operator says to check that under all circumstances the function will not crash with a pattern-match error. The module is actually slightly more involved, but this is all detail which Catch will shortly hide into a library.
A future intention is to have a tool which automatically generates such a module from a library. This then allows the person performing the checking to simply point at a library, with no additional infrastructure.
Step 4: Test using Catch
This step is the first time we actually invoke Catch - and its as simple as a single line:
> catch Catch.hs -errors -partial
And thats it, now Catch gives you all the necessary information to start fixing your code. I emailed a summary of the results as given by Catch to the XMonad list: http://www.haskell.org/pipermail/xmonad/2007-May/000196.html
At this point I hopped on IRC, and in discussions with sjannsen talked him through installing Catch and the necessary dependencies. Once he had this installed, he was able to modify the StackSet API and implementation to guarantee that no pattern match errors are raised. After all of this, now running Catch over the test script gives success.
A lesson to take away
There were only two sticking points in running Catch over XMonad. The first was that Yhc can't always compile the code, and may require slight tweaks to be made. There are two solutions to fixing this, we can either fix Yhc, or I can make Catch use GHC Core. The GHC Core solution shouldn't be too much work, once GHC has a library for external Core.
The second sticking point is that installing Catch is a lot harder than it should be. A little bit of Cabal magic and a proper release should squash these problems easily.
So what lessons did I learn? Perhaps the thing that surprised me most is how easily someone else was able to get to grips with the Catch tool. This gives me a strong sense of hope that average users may be able to employ the Catch tool upon their programs, either in this version of a future version.
Monday, April 30, 2007
Phantom Types for Real Problems
As part of my work on Hoogle 4 I've been bashing my deferred binary library quite a lot. I encountered one bug which I hadn't considered, and was able to come up with a solution, using phantom types. I've read about phantom types before, but never actually put them into practice!
The idea of the deferred binary library is that writing instances should be as short as possible - they don't need to be massively high performance, and I wanted to see if I could do it with minimal boilerplate. Each instance needs to be able to both save and load a value - which means it needs to do some sort of pattern-match (to see which value it has), and have the constructor available (to create a new value). The shortest scheme I was able to come up with is:
The idea is that to save a value, you step through the list trying to match each constructor, using Control.Exception.catch to see if the value does not match. Once you have matched, you save an index, and the components. To load a value, you take the index and pick the correct construction. This time, you deliberately do not mention any of the fields, and by remaining lazy on the fields, the pattern match is not invoked. This solution took quite a lot of thought to arrive at, but does minimize the size of the instance declarations.
The instance relies crucially on the laziness/strictness of the functions - the load function must not examine any of its arguments (or you will pattern-match fail), the save function must examine at least one argument (to provoke pattern-match failure). After writing a description such as this, I am sure some users will have spotted the issue!
The problem here is 0-arity constructors, the load code works just fine, but the save code has no fields it can demand to ensure the correct constructor has been reached. I encountered this bug in Hoogle 4 - it is subtle, and in a pile of instance rules, these 0-arity cases can easily be overlooked. The solution is to introduce a new operator, (<<!), whose only purpose is to strictly demand something:
This (<<!) operator is only required for 0-arity constructors, but is not harmful in other cases. Now the correct fix has been decided upon, we can fix the Hoogle instances. Unfortunately, we can still write the incorrect case, and will get no warning - a bug just waiting to happen. The solution to this is to use phantom types.
The whole point of a phantom type is that it doesn't actually reflect real data, but exists only at the type level, artificially restricting type signatures to ensure some particular property. In our case, the property we want to ensure is that "unit" is never used on its own, but either with (<<), (<<~) or (<<!). We can achieve this by giving unit a different type, even though in reality all operate on the same type of data:
Now the type of unit is PendingNone, but the type of all other operations is PendingSome. By demanding that the list "defer" accepts is all PendingSome, we are able to raise a type error if the (<<!) is missed.
By using phantom types, a easy to make error can be guarded against statically. Plus, its not very hard to do!
The idea of the deferred binary library is that writing instances should be as short as possible - they don't need to be massively high performance, and I wanted to see if I could do it with minimal boilerplate. Each instance needs to be able to both save and load a value - which means it needs to do some sort of pattern-match (to see which value it has), and have the constructor available (to create a new value). The shortest scheme I was able to come up with is:
data Foo = Foo String Bool | Bar Foo
instance BinaryDefer Foo where
bothDefer = defer
[\ ~(Foo a b) -> unit Foo << a << b
,\ ~(Bar a) -> unit Bar << a
]
The idea is that to save a value, you step through the list trying to match each constructor, using Control.Exception.catch to see if the value does not match. Once you have matched, you save an index, and the components. To load a value, you take the index and pick the correct construction. This time, you deliberately do not mention any of the fields, and by remaining lazy on the fields, the pattern match is not invoked. This solution took quite a lot of thought to arrive at, but does minimize the size of the instance declarations.
The instance relies crucially on the laziness/strictness of the functions - the load function must not examine any of its arguments (or you will pattern-match fail), the save function must examine at least one argument (to provoke pattern-match failure). After writing a description such as this, I am sure some users will have spotted the issue!
data Bool = False | True
instance BinaryDefer Bool where
bothDefer = defer
[\ ~(False) -> unit False
,\ ~(True) -> unit True
]
The problem here is 0-arity constructors, the load code works just fine, but the save code has no fields it can demand to ensure the correct constructor has been reached. I encountered this bug in Hoogle 4 - it is subtle, and in a pile of instance rules, these 0-arity cases can easily be overlooked. The solution is to introduce a new operator, (<<!), whose only purpose is to strictly demand something:
instance BinaryDefer Bool where
bothDefer = defer
[\ ~(x@False) -> unit False <<! x
,\ ~(x@True) -> unit True <<! x
]
This (<<!) operator is only required for 0-arity constructors, but is not harmful in other cases. Now the correct fix has been decided upon, we can fix the Hoogle instances. Unfortunately, we can still write the incorrect case, and will get no warning - a bug just waiting to happen. The solution to this is to use phantom types.
The whole point of a phantom type is that it doesn't actually reflect real data, but exists only at the type level, artificially restricting type signatures to ensure some particular property. In our case, the property we want to ensure is that "unit" is never used on its own, but either with (<<), (<<~) or (<<!). We can achieve this by giving unit a different type, even though in reality all operate on the same type of data:
data PendingNone
data PendingSome
unit :: a -> Pending a PendingNone
(<<) :: BinaryDefer a => Pending (a -> b) p -> a -> Pending b PendingSome
(<<~) :: BinaryDefer a => Pending (a -> b) p -> a -> Pending b PendingSome
(<<!) :: Pending a p -> a -> Pending a PendingSome
Now the type of unit is PendingNone, but the type of all other operations is PendingSome. By demanding that the list "defer" accepts is all PendingSome, we are able to raise a type error if the (<<!) is missed.
By using phantom types, a easy to make error can be guarded against statically. Plus, its not very hard to do!
Friday, April 27, 2007
Hoogle 4 type matching
I've done some more work on Hoogle 4, and can now create a database from a textual file, then perform text searches upon the database and show the results. It is basically a command line version of Hoogle restricted to text search only. A lot of the time went on debugging binarydefer, which has saved a lot of effort and meant that all the mistakes due to complex file prodding and seeking are localised in a library which can be reused throughout. Hoogle 4 is both a library and a program, and now I have a minimal API which is mostly free from any monads.
Now I get on to the fun bit, how to do type search. I've done type search in three entirely separate ways:
Of course, it wouldn't be a new version of Hoogle if I didn't have a new way to perform type searches :) The new type searches are based on six operations, the idea is that you start with a target type (what the user queried for), and transform the type into the source type (from the source code). Each transformation has a cost associated with it, and can be run in both directions. I finalised the six tranformation steps some time ago, and they have been floating around on my desk as a piece of paper - not a safe place for paper to live. As such, I've decided to write them up there, in the hope that Google won't loose them.
Each operation has an associated symbol, I've included these symbols in \tex as as well Unicode.
Alpha conversion \alpha (α): a --> b. The standard lambda calculus rule, but this time alpha conversion is not free.
Unboxing \box (□) : m a --> a. Given something in a box, take it out. For example Maybe a --> a would be an example.
Restriction (!): M --> a. Given something concrete like Bool, turn it into a free variable.
Aliasing (=): a --> alias(a). This makes use of the type keyword in Haskell, for example String --> [Char], because type String = [Char].
Context \Rightarrow (⇒): C a => a --> a. Drops the context on a variable, i.e. Eq a => a --> a.
Membership \in (∈): C M => M --> C a => a. For example, Bool --> Eq a => a.
There are some additional restrictions, and methods for applying these rules, but these are the core of the system.
Now I get on to the fun bit, how to do type search. I've done type search in three entirely separate ways:
- Hoogle 1: Alpha conversion with missing arguments
- Hoogle 2: Unification
- Hoogle 3: Edit distance
Of course, it wouldn't be a new version of Hoogle if I didn't have a new way to perform type searches :) The new type searches are based on six operations, the idea is that you start with a target type (what the user queried for), and transform the type into the source type (from the source code). Each transformation has a cost associated with it, and can be run in both directions. I finalised the six tranformation steps some time ago, and they have been floating around on my desk as a piece of paper - not a safe place for paper to live. As such, I've decided to write them up there, in the hope that Google won't loose them.
Each operation has an associated symbol, I've included these symbols in \tex as as well Unicode.
Alpha conversion \alpha (α): a --> b. The standard lambda calculus rule, but this time alpha conversion is not free.
Unboxing \box (□) : m a --> a. Given something in a box, take it out. For example Maybe a --> a would be an example.
Restriction (!): M --> a. Given something concrete like Bool, turn it into a free variable.
Aliasing (=): a --> alias(a). This makes use of the type keyword in Haskell, for example String --> [Char], because type String = [Char].
Context \Rightarrow (⇒): C a => a --> a. Drops the context on a variable, i.e. Eq a => a --> a.
Membership \in (∈): C M => M --> C a => a. For example, Bool --> Eq a => a.
There are some additional restrictions, and methods for applying these rules, but these are the core of the system.
Wednesday, April 25, 2007
More Hoogle progress
I haven't done much on Hoogle 4 in quite a while, and since I keep telling people that various bugs will be "fixed in Hoogle 4", it seems only polite to fix those bugs in the near future. I decided that this evening I would focus on Hoogle 4, since I was slowly going insane from writing academic papers. I'm now just about to go to bed, so thought I would summarise what I did.
One of the things that has been slowing me down on Hoogle is the fact that I rarely get a chance to work on it, and when I do that means I have to refamiliarise myself with the code base. Each time I do this, I forget something, forget what I was working for, and generally end up slowing down development. It also means that working on Hoogle for "an odd half hour" is not practical, it takes at least a couple of hours to get up to speed. In order to solve this, I've done some diagrams of the module structure, and the main Hoogle database. They may not mean much to anyone else, but I hope they are enough to keep my mind fresh with where things go.
As part of documenting the module structure, it also gives a chance to reflect on where the module structure is a bit unclear, and modify as necessary. Previously the module structure had DataBase and Item each being dependent on each other - with tricks like having an extra field in Item which was of a parametrised type, i.e:
data Item a = Item {name :: String, typeSig :: TypeSig, other :: a}
Fortunately now all that is gone, and the structure is a lot more logical.
The other thing I've been doing is moving to the Deferred Binary library. Part of the reason for Hoogle 4 becoming bogged down is the creation of a central database that is loaded on demand, and contains tries etc to perform efficient searches. Unfortunately, this loading on demand aspect had infected the entire code, resulting in a big IO Monad mess. It was slightly more pleasant than coding in C, but all the low-level thoughts had seeped through, requiring careful though, slow progress and frequent mistakes.
To take one example, the Hoogle.DataBase.Texts module, which is responsible for performing all textual searches and storing the lazily-loaded trie. Compare the old version and the current version. The code has shrunk from 186 lines to 65 - of which only about 30 are real code. The IO Monad is nowhere to be seen - everything is pure. The really low-level functions such as sizeTree and layoutTree have gone entirely.
I'm not sure when I will next be able to get to Hoogle 4, but next time I hope to start working on it faster, and that the cleaner code makes for happier coding!
Note: I have started displaying adverts on this blog because it was only a button click away (very impressive integration by Google), it seemed like a fun thing to try and that the adverts in Gmail are sometimes quite helpful. I have deliberately picked to not show too many adverts, placed them off to the side where they won't interfere with reading and tried to keep it minimal - but if they are annoying please let me know. I am going to donate whatever money (if any) from this to charity - but please don't take that as an incentive to artificially click on adverts you aren't interested in.
One of the things that has been slowing me down on Hoogle is the fact that I rarely get a chance to work on it, and when I do that means I have to refamiliarise myself with the code base. Each time I do this, I forget something, forget what I was working for, and generally end up slowing down development. It also means that working on Hoogle for "an odd half hour" is not practical, it takes at least a couple of hours to get up to speed. In order to solve this, I've done some diagrams of the module structure, and the main Hoogle database. They may not mean much to anyone else, but I hope they are enough to keep my mind fresh with where things go.
As part of documenting the module structure, it also gives a chance to reflect on where the module structure is a bit unclear, and modify as necessary. Previously the module structure had DataBase and Item each being dependent on each other - with tricks like having an extra field in Item which was of a parametrised type, i.e:
data Item a = Item {name :: String, typeSig :: TypeSig, other :: a}
Fortunately now all that is gone, and the structure is a lot more logical.
The other thing I've been doing is moving to the Deferred Binary library. Part of the reason for Hoogle 4 becoming bogged down is the creation of a central database that is loaded on demand, and contains tries etc to perform efficient searches. Unfortunately, this loading on demand aspect had infected the entire code, resulting in a big IO Monad mess. It was slightly more pleasant than coding in C, but all the low-level thoughts had seeped through, requiring careful though, slow progress and frequent mistakes.
To take one example, the Hoogle.DataBase.Texts module, which is responsible for performing all textual searches and storing the lazily-loaded trie. Compare the old version and the current version. The code has shrunk from 186 lines to 65 - of which only about 30 are real code. The IO Monad is nowhere to be seen - everything is pure. The really low-level functions such as sizeTree and layoutTree have gone entirely.
I'm not sure when I will next be able to get to Hoogle 4, but next time I hope to start working on it faster, and that the cleaner code makes for happier coding!
Note: I have started displaying adverts on this blog because it was only a button click away (very impressive integration by Google), it seemed like a fun thing to try and that the adverts in Gmail are sometimes quite helpful. I have deliberately picked to not show too many adverts, placed them off to the side where they won't interfere with reading and tried to keep it minimal - but if they are annoying please let me know. I am going to donate whatever money (if any) from this to charity - but please don't take that as an incentive to artificially click on adverts you aren't interested in.
Monday, April 23, 2007
Boilerplate considered harmful
At the moment I'm working on a boilerplate removal for Haskell, which is faster (runtime), shorter (code), more type safe and requires fewer extensions than Scrap Your Boilerplate (SYB). However, since I haven't finished and released a stable version, I can't really recommend people use that. The reason I started working on this is because I was unaware of SYB when I started. Last week I also introduced someone to SYB, who had done quite a bit of Haskell programming, but had not stumbled across SYB. As a result, I think it needs a bit more attention - SYB is one of the strengths of Haskell!
Disadvantages
Before saying how great SYB is, its important to point out the things that make it not so great:
A data structure
Before showing some operations, I'm going to first introduce a data structure on which we can imagine operations are performed. I don't like the example from the SYB benchmark - it feels like an XML file (as is the stated intention), which means that the logic behind it is a bit disturbed. So instead I'll pick a data type like an imperative programming language:
{-# OPTIONS_GHC -fglasgow-exts #-}
import Data.Generics
data Expr = Var String | Lit Int | Call String [Expr] deriving (Data, Typeable)
data Stmt = While Expr [Stmt] | Assign String Expr | Sequence [Stmt] deriving (Data,Typeable)
We define the data type as normal, adding deriving for Data and Typeable - the two key SYB types. We also add an import and a flag, just to get the GHC machinery working for the derivings.
Queries
So lets imagine you have to get a list of all literals. In SYB this is easy:
extractLits :: Data a => a -> [Int]
extractLits = everything (++) ([] `mkQ` f)
where f (Lit x) = [x] ; f _ = []
Wow, easy! This function will operate on anything which has a Data instance, so you can run it on an Expr, Stmt, [Stmt], [Either Stmt Expr] - the choice is yours. For the purposes of a short introduction, I'd recommend treating all the bits except the "f" as just something you write - read the full SYB paper to get all the details of what everything can be used for.
Traversals
Now lets negate all the literals, we have:
negateLits :: Data a => a -> a
negateLits = everywhere (mkT f)
where f (Lit x) = Lit (negate x) ; f x = x
Again, its pretty easy. And once again, consider all apart from the "f" as just something you write.
The gains in code reduction that can be made with SYB are quite substantial, and by removing the boilerplate you get code which can be reused more easily. Boilerplate code is bad, and should be removed where necessary.
Disadvantages
Before saying how great SYB is, its important to point out the things that make it not so great:
- Only implemented in GHC - sorry to the poor Hugs users
- Requires rank-2 types, which means its not actually Haskell 98
- Occassionally the rank-2-ness infects the code you write, with unfortunate error messages (although this is not that common)
A data structure
Before showing some operations, I'm going to first introduce a data structure on which we can imagine operations are performed. I don't like the example from the SYB benchmark - it feels like an XML file (as is the stated intention), which means that the logic behind it is a bit disturbed. So instead I'll pick a data type like an imperative programming language:
{-# OPTIONS_GHC -fglasgow-exts #-}
import Data.Generics
data Expr = Var String | Lit Int | Call String [Expr] deriving (Data, Typeable)
data Stmt = While Expr [Stmt] | Assign String Expr | Sequence [Stmt] deriving (Data,Typeable)
We define the data type as normal, adding deriving for Data and Typeable - the two key SYB types. We also add an import and a flag, just to get the GHC machinery working for the derivings.
Queries
So lets imagine you have to get a list of all literals. In SYB this is easy:
extractLits :: Data a => a -> [Int]
extractLits = everything (++) ([] `mkQ` f)
where f (Lit x) = [x] ; f _ = []
Wow, easy! This function will operate on anything which has a Data instance, so you can run it on an Expr, Stmt, [Stmt], [Either Stmt Expr] - the choice is yours. For the purposes of a short introduction, I'd recommend treating all the bits except the "f" as just something you write - read the full SYB paper to get all the details of what everything can be used for.
Traversals
Now lets negate all the literals, we have:
negateLits :: Data a => a -> a
negateLits = everywhere (mkT f)
where f (Lit x) = Lit (negate x) ; f x = x
Again, its pretty easy. And once again, consider all apart from the "f" as just something you write.
The gains in code reduction that can be made with SYB are quite substantial, and by removing the boilerplate you get code which can be reused more easily. Boilerplate code is bad, and should be removed where necessary.
Thursday, April 19, 2007
Visual Basic, the story
Today on the Haskell mailing list, someone confused VBScript and VBA. Its not really surprising, the "Visual Basic" or "VB" name has been attached to at least 3 entirely different programming languages! This is an attempt to clear up the confusion. My first programming language (after .bat) was Visual Basic, and I loved it. I've worked on Excel/Word programs using VB, written applications for money in VB, and lots more besides - its a great language. Often people criticize VB for being "under powered" or a "beginners language" - those people are wrong - but that's not something I'm going to cover here :-) [Technical note: I may have got some of this wrong, I was a user of the language - not an implementer]
Visual Basic 3
We'll start the story at Visual Basic 3, because that's the first version I ever used. My Sixth Form would copy it to floppy disk if you bought in 3, which is basically school sponsored piracy. Anyway, this language was an imperative language, with build in support for graphical interfaces.
You can spot a VB 3 program a mile away, they look clunky and alas VB made it really easy to change the background colour of a form. The ability to easily change the colours made it a hotbed for garish colours - does you inhouse application have pastel shades of red? If so its either a C programmer who went to a lot of work, or more likely, a VB programmer without any sense of style. I've seen these apps running on point-of-sale terminals in some shops.
Visual Basic 5/6
I'm going to lump these two versions into one, there were some changes, but not many. Continuing the same trend as VB 3, but moving towards being an object orientated language. This language had a very strong COM interoperation - all VB objects were COM objects, all COM objects could be used in VB. The COM ability made it ideal for many things, and opened up lots of easy to use libraries. All windows become objects, and some of the clunky bits in VB 3 got depreciated in favour of the newer methods, but most programs still worked exactly as before.
Alas VB 6 still allows the background colours of a form to be set, but if you don't (please don't!) the program looks very Windows native - much more than Java or even C#.
Visual Basic for Applications (VBA)
At the time of VB 5, Microsoft moved over to using VB as the language of scripting in Office, replacing WordScript etc. The VBA language is VB, but rather than have the VB libraries, it has the Office libraries. The languages are identical in general use.
VBScript
Microsoft also decided they needed a JavaScript (or JScript as they call it, or ECMAScript as dull people call it) competitor. They decided to repurpose VB, changing it slightly to give it a more scripting feel. If you use IE, you can run VBScripts in the browser. If you like email viruses you can run the .vbs files you can your inbox. If you have active scripting installed, you can run .vbs files at the command line.
But please, don't use VBScript. JavaScript is a much nicer language, and works everywhere VBScript does and in more places besides. The language VBScript should quietly go away and die. There is one exception: ASP only provides one method (uploading a binary file) for VBScript but not JavaScript. As a result, I do have a website written in VBScript which I have to maintain.
VB.NET
And finally we get to the newest edition, or ¬VB.NET as I will refer to it. When changing to C# with .NET, Microsoft decided that shunning all the VB developers would be a bad idea, so instead they shunned them and wrote a syntax wrapper round C#. The ¬VB.NET language is a perfectly fine language, but its not VB. Things like late binding have been removed, the syntax has been made more regular, the object facilities have totally changed etc. If you have a VB project of any mild complexity, then you'll not get very far with the automatic converter.
If you are a VB developer looking to move towards the new .NET framework, I'd look at both ¬VB.NET and C#, before deciding which one to pick. The differences aren't that major, but at the time I was learning (.NET 1.0 beta) the ¬VB.NET was clearly the unloved younger brother of C# - the examples were all C#, and it was clearly the favoured language. Now both languages have evolved so they are not as similar, but neither is worthy of the VB name.
Me and VB
VB was my first language, and my "first choice" language for years. After learning C I initially poured scorn on VB for not being a "real language", then I realised I was an idiot and that VB is a lot better for most application programming than C, and you can always interface to a C .dll if you must. Now Haskell and C# (for GUI's) have become my standard languages - I haven't started up VB 6 for quite a while. I've got a few programs written in VB 6 around that I technically maintain, but none that I've had any reports on in ages, and none that I can imagine working on. I've got at least 50 programs in my VB directory, but I've forgotten quite where I put my VB directory - its certainly not been opened in a while.
Even though I may not use stand alone VB 6 anymore, I still maintain and actively work on some VBA solutions for accountants in Excel, and a couple of website templating systems using VBA in Word. I also develop and maintain a corporate website using VBScript, which requires new features adding at least once a year. VB is not yet dead, but its definitely going that way.
Visual Basic 3
We'll start the story at Visual Basic 3, because that's the first version I ever used. My Sixth Form would copy it to floppy disk if you bought in 3, which is basically school sponsored piracy. Anyway, this language was an imperative language, with build in support for graphical interfaces.
You can spot a VB 3 program a mile away, they look clunky and alas VB made it really easy to change the background colour of a form. The ability to easily change the colours made it a hotbed for garish colours - does you inhouse application have pastel shades of red? If so its either a C programmer who went to a lot of work, or more likely, a VB programmer without any sense of style. I've seen these apps running on point-of-sale terminals in some shops.
Visual Basic 5/6
I'm going to lump these two versions into one, there were some changes, but not many. Continuing the same trend as VB 3, but moving towards being an object orientated language. This language had a very strong COM interoperation - all VB objects were COM objects, all COM objects could be used in VB. The COM ability made it ideal for many things, and opened up lots of easy to use libraries. All windows become objects, and some of the clunky bits in VB 3 got depreciated in favour of the newer methods, but most programs still worked exactly as before.
Alas VB 6 still allows the background colours of a form to be set, but if you don't (please don't!) the program looks very Windows native - much more than Java or even C#.
Visual Basic for Applications (VBA)
At the time of VB 5, Microsoft moved over to using VB as the language of scripting in Office, replacing WordScript etc. The VBA language is VB, but rather than have the VB libraries, it has the Office libraries. The languages are identical in general use.
VBScript
Microsoft also decided they needed a JavaScript (or JScript as they call it, or ECMAScript as dull people call it) competitor. They decided to repurpose VB, changing it slightly to give it a more scripting feel. If you use IE, you can run VBScripts in the browser. If you like email viruses you can run the .vbs files you can your inbox. If you have active scripting installed, you can run .vbs files at the command line.
But please, don't use VBScript. JavaScript is a much nicer language, and works everywhere VBScript does and in more places besides. The language VBScript should quietly go away and die. There is one exception: ASP only provides one method (uploading a binary file) for VBScript but not JavaScript. As a result, I do have a website written in VBScript which I have to maintain.
VB.NET
And finally we get to the newest edition, or ¬VB.NET as I will refer to it. When changing to C# with .NET, Microsoft decided that shunning all the VB developers would be a bad idea, so instead they shunned them and wrote a syntax wrapper round C#. The ¬VB.NET language is a perfectly fine language, but its not VB. Things like late binding have been removed, the syntax has been made more regular, the object facilities have totally changed etc. If you have a VB project of any mild complexity, then you'll not get very far with the automatic converter.
If you are a VB developer looking to move towards the new .NET framework, I'd look at both ¬VB.NET and C#, before deciding which one to pick. The differences aren't that major, but at the time I was learning (.NET 1.0 beta) the ¬VB.NET was clearly the unloved younger brother of C# - the examples were all C#, and it was clearly the favoured language. Now both languages have evolved so they are not as similar, but neither is worthy of the VB name.
Me and VB
VB was my first language, and my "first choice" language for years. After learning C I initially poured scorn on VB for not being a "real language", then I realised I was an idiot and that VB is a lot better for most application programming than C, and you can always interface to a C .dll if you must. Now Haskell and C# (for GUI's) have become my standard languages - I haven't started up VB 6 for quite a while. I've got a few programs written in VB 6 around that I technically maintain, but none that I've had any reports on in ages, and none that I can imagine working on. I've got at least 50 programs in my VB directory, but I've forgotten quite where I put my VB directory - its certainly not been opened in a while.
Even though I may not use stand alone VB 6 anymore, I still maintain and actively work on some VBA solutions for accountants in Excel, and a couple of website templating systems using VBA in Word. I also develop and maintain a corporate website using VBScript, which requires new features adding at least once a year. VB is not yet dead, but its definitely going that way.
Subscribe to:
Posts (Atom)

{kind=link}
{kind=link}