I just got an email:
"I've got hat-observe working on my code, which makes me very happy."
This is a happy Hat user, who is using my Windows port. As far as I know, this is the first Hat user on Windows who has actually got a real project going through which they really want to debug - not just test stuff.
This makes me very happy too :)
Thursday, October 26, 2006
Saturday, October 21, 2006
30% faster than GHC!
I have been working on a back end to my analysis framework Catch for a while, I do lots of transformations as part of Catch, some of which speed up the code, so hooking a back end up seems sensible. Using this back end, I can be 30% faster than GHC.
Before I show any pretty graphs, there are few big and important disclaimers:
And so on to some pretty graphs of *HC vs GHC on the prime number benchmark:
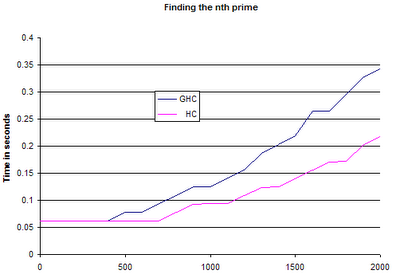
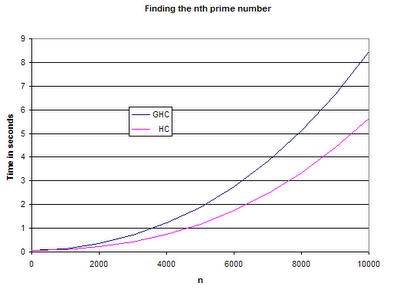
These numbers show a pretty much one third increase in speed.
One of my future tasks is to hook this directly up to a code generator, and hopefully my speed will increase even further - at the moment I have to add things in to make the output valid Haskell which slows down the generated code. A custom back end would help with this, plus I have other techniques for speeding up the back end given some of the "knowledge" accumulated by Catch. I am reasonably confident that GHC is not doing too much of the heavy work when compiling my code, as compiling without any optimisation does not penalise my GHC output too much.
How do I get fast code?
I take the Yhc compiler, and generate Yhc.Core. I take all the Core generated for all bits in the program and splat them together, including the Prelude etc. I run some analysis passes on this code, including making the code completely first order, a little bit of deforestation and a touch of partial evaluation. I then output Haskell, however my Core language is not a subset of Haskell, so some additional things need to be handled.
Will this only work for Primes?
Hopefully not! In theory the back end is general purpose, and should work for anything. In practice, I'm still working on it, and not everything is finished yet.
Whole program analysis? Thats slow!
Not really, I develop Catch in Hugs, it takes around 10 seconds to compile Primes in Hugs, using an entirely unoptimised pipeline - I even use associative lists for function name lookup - and still the performance is not too bad. Only a very small number of the steps I perform are whole program, and the ones that are only get done once in a linear fasion. It probably won't scale to "a whole compiler", but it can certainly hit 1000 line programs with no issue.
What's next?
Stop getting distracted by developing a compiler, and get back to my PhD!
Before I show any pretty graphs, there are few big and important disclaimers:
- I use GHC as a back end
- This means that GHC optimises my code as well!
- Benchmarked against GHC 6.4.2, using -O2
- Only tested on one single file! Prime numbers, from the nofib suite.
- All experiments run on a P4, 3GHz
- All experiments run 5 times, and the lowest number recorded
- I do whole program analysis
And so on to some pretty graphs of *HC vs GHC on the prime number benchmark:
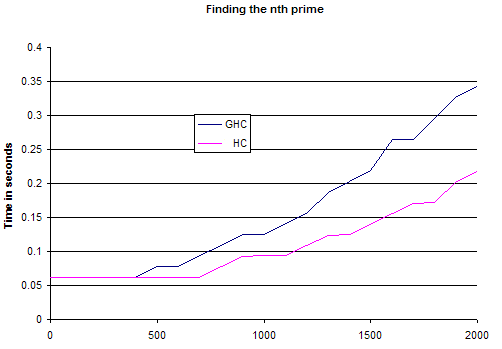
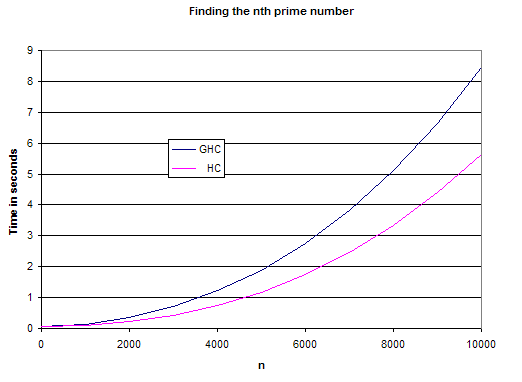
These numbers show a pretty much one third increase in speed.
One of my future tasks is to hook this directly up to a code generator, and hopefully my speed will increase even further - at the moment I have to add things in to make the output valid Haskell which slows down the generated code. A custom back end would help with this, plus I have other techniques for speeding up the back end given some of the "knowledge" accumulated by Catch. I am reasonably confident that GHC is not doing too much of the heavy work when compiling my code, as compiling without any optimisation does not penalise my GHC output too much.
How do I get fast code?
I take the Yhc compiler, and generate Yhc.Core. I take all the Core generated for all bits in the program and splat them together, including the Prelude etc. I run some analysis passes on this code, including making the code completely first order, a little bit of deforestation and a touch of partial evaluation. I then output Haskell, however my Core language is not a subset of Haskell, so some additional things need to be handled.
Will this only work for Primes?
Hopefully not! In theory the back end is general purpose, and should work for anything. In practice, I'm still working on it, and not everything is finished yet.
Whole program analysis? Thats slow!
Not really, I develop Catch in Hugs, it takes around 10 seconds to compile Primes in Hugs, using an entirely unoptimised pipeline - I even use associative lists for function name lookup - and still the performance is not too bad. Only a very small number of the steps I perform are whole program, and the ones that are only get done once in a linear fasion. It probably won't scale to "a whole compiler", but it can certainly hit 1000 line programs with no issue.
What's next?
Stop getting distracted by developing a compiler, and get back to my PhD!
Subscribe to:
Posts (Atom)
